The process of identification and analysis of crucial factors, such as the identity of a criminal, plays a critical role in digital forensics investigation (DFI), This DFI process entails the extensive utilisation of data and human-directed data analysis, which is often time-consuming and subjective. Hence, an automated process of evidence extraction from voluminous datasets would be essential.
One strategy for facilitating the task of processing forensic data would be a system capable of extracting attributes such as gender, age, and ethnicity from human voice recordings could aid in speaker identification. Since, only a small number of systems currently focus on identifying ethnicity and age, this project focused on building an automated system that could predict gender, age and ethnicity from voice recordings, using advanced techniques such as support vector machines (SVMs). The proposed system builds upon existing knowledge, using available datasets of thousands of labelled voice samples, and incorporates enhancements that would improve its predictive capabilities, while remaining applicable to realistic data.
In order to create an optimal operational system that could classify unlabelled voice samples, good, balanced and labelled training and testing datasets would be crucial. Hence, any biases present in the dataset were filtered by removing voice samples with missing values and other unwanted entries containing attribute values that did not possess enough characteristics to be utilised in training and testing the model. Moreover, since the dataset used was quite extensive, it was ensured that the selected samples were indicative of the voice distribution, by employing a random selection function with equal amounts of samples from each attribute group and category. Feature transformation, engineering and extraction were then carried out to facilitate more effective learning by the model.
The extracted features included spectral centroid, spectral bandwidth, spectral roll-off, and a set of 20 Mel-frequency cepstral coefficients (MFCCs) features. The top 22 features were selected for use in the model-selection stage, where two types of classifiers, specifically the SVM and the random forest classifier were considered. The hyper-parameters of both classifiers were tweaked to optimise the accuracy of the system. It was then concluded that the SVM classifier produced higher F1 scores, and was therefore utilised as the primary model for the automated system. Each attribute-prediction model was saved for use in the application of the model.
Finally, a model incorporating prediction for gender, age, and ethnicity, was also constructed. This was achieved by initially loading the pre-trained prediction models and encoders, and subsequently applying the same preprocessing and feature-engineering procedures on the unlabelled audio. Predictions were then generated by calculating the gender, age, and ethnicity with the use of the loaded models. The numerical predicted values were transformed back to their original values by using the loaded encoders.
An evaluation was carried out comprising the predicted output of the targeted attributes for each voice sample. The accuracy of the prediction models varied, with the gender-prediction model yielding an accuracy of 91%, whereas the age-prediction model delivered an accuracy of 68%; the ethnicity-prediction model produced an accuracy of almost 73%.
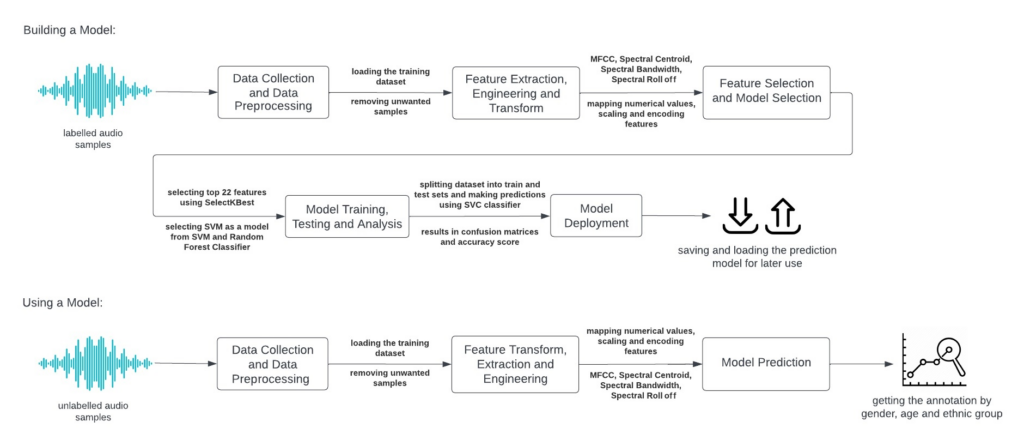
Figure 1. Diagram representing the processes involved in the proposed audio-samples detection system
Student: Nicole Bezzina
Supervisor : Dr Joseph Vella