Deterministic finite-state automata (DFA) are computational machines that are able to accept or reject words, depending on whether they belong to the target regular language they are representing. DFA learning is the task of learning the smallest DFA from a training set of strings that belong and do not belong to the regular language, respectively. Other learning algorithms might not make use of a training set and instead require oracles to provide specific examples.
The aim of this final-year-project was to extend DfaGo (an existing DFA learning toolkit written in Go) to allow the implementation of certain algorithms in Python. The choice of extending DfaGo was based on the following considerations: it contains robust implementations of many important data structures; it has been heavily optimised for performance; it is well documented; and it implements many important DFA learning algorithms. While DfaGo (in its current state) would be suitable for state-merging ‘type’ algorithms, it has weak support for other learning algorithms based on neural computational models. Particularly, Python has strong and highly optimised implementations of random neural networks (RNNs), long short-term memory (LSTM), and transformers that could also be used for learning regular languages.
This project consisted in implementing, and testing an interface between DfaGo and the Python runtime using a client/server model and designing a communication protocol for the task. The first approach was binding the Go and Python runtimes together. However, returns from Python back to Go were not being updated, and hence this was not considered to be a viable solution. The second approach, which was the one that was chosen eventually, was to use a client-server communication protocol where Python could ask the following: membership queries; if a word was in the language and receiving a true or false in return; and equivalence queries ‒ where a hypothesis DFA would be provided, where Go could either return a word that is a counterexample, meaning that would be treated differently by the hypothesis DFA and the DFA that is being learnt.
As a proof of concept to test this interface, the L Star (L*) algorithm devised by Dana Angluin was implemented [1]. It was chosen due to the high number of membership and equivalence queries that it asks, making it a communication-intensive algorithm. This made it possible to establish the performance cost of the interface more adequately, as for every query Python would need to interact with the interface to get a response from the Go server.
The L* algorithm was implemented in three environments, namely, Python, Go, and Go-Python using the interface to communicate between the two. The runtime and their performance were then compared to observe the effect on performance of using the interface, compared to the other two environments. Figure 1. outlines how the communication protocol would function at a high-level when learning using L* in particular.
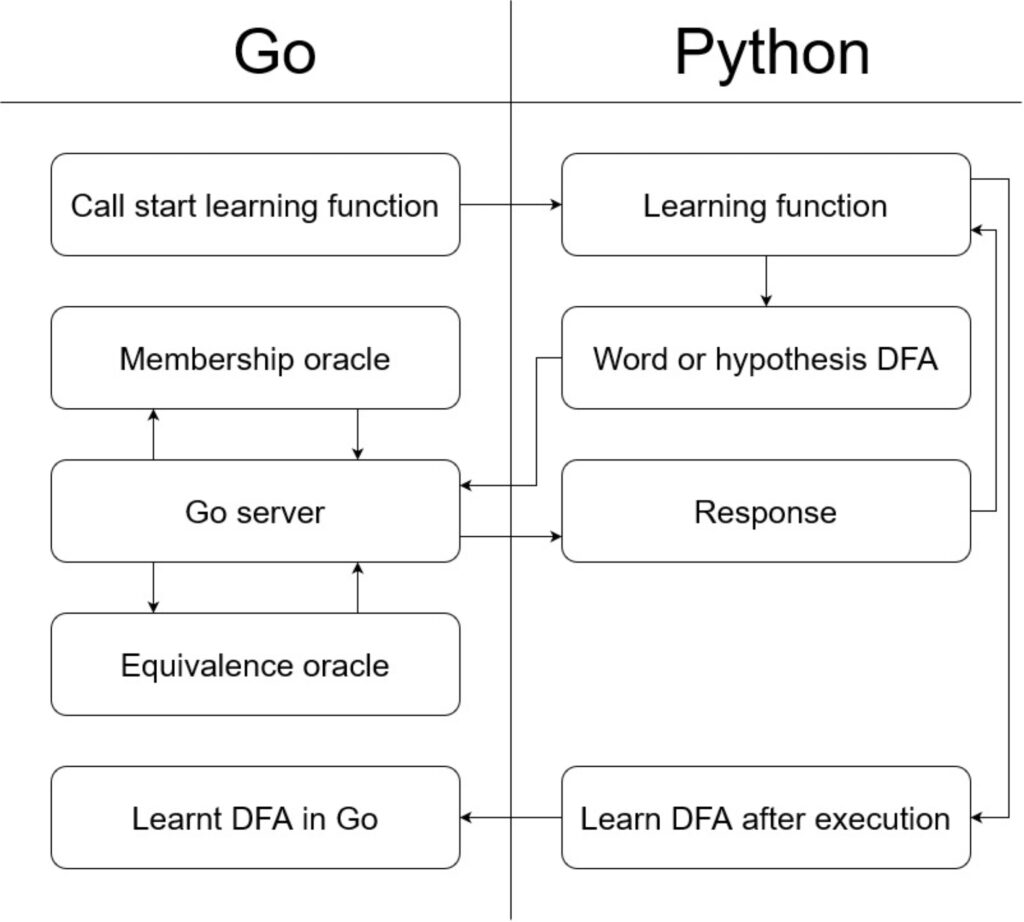
Figure 1. A sample run of L*, using the interface described in the article
Student: Mathias Vaaben
Supervisor : Dr Kristian Guillaumier