In Malta, there are 7,100 vision-impaired (1.9% of the Maltese population), and over 24,000 illiterate (6.4% of the Maltese population), Maltese speakers [1]. These people are unable to consume any content written in Maltese, be it a book, a news article, or even a simple Facebook post. This dissertation sets out to solve that problem by creating a Text to Speech (TTS) system for the Maltese language.
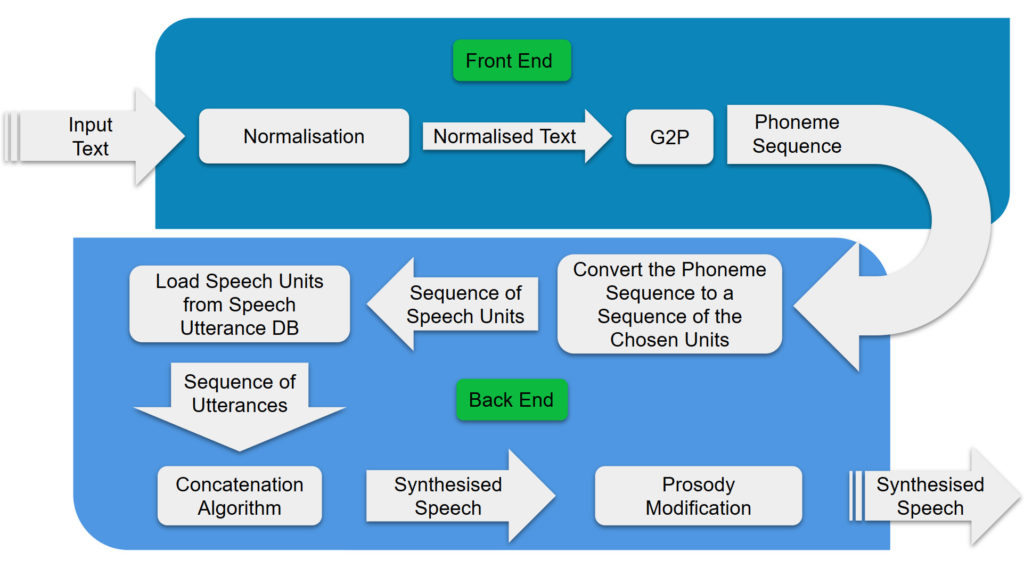
While there has been work in the area, at the time of writing there are no available TTS systems for Maltese, thus almost the entire system had to be built from scratch. In light of this, a Diphone-Based Concatenative Speech System was chosen as the type of synthesiser to implement. This was due to the minimal amount of data needed, requiring less than 20 minutes of recorded speech.
A simple `Text Normalisation’ component was built, which converts integers between 0 and 9,999 written as numerals to their textual form. While this is far from covering all the possible forms of Non-Standard Words (NSWs) in Maltese, the modular nature in which it was built allows for easy upgrading in future work. A ‘Grapheme to Phoneme (G2P)’ component which then converts the normalised text into a sequence of phonemes (basic sounds) that make up the text was also created, based on an already existing implementation by Crimsonwing [2].
Three separate `Diphone Databases’ were made available to the speech synthesiser. One of these is the professionally recorded English Diphone database FestVox’s ‘CMU US KAL Diphone’1. The second and third were created as part of this work, one with diphones manually extracted from the recorded carrier phrases in Maltese, the other with diphones automatically extracted using Dynamic Time Warping (DTW). The Time Domain- Pitch Synchronous OverLap Add (TD-PSOLA) concatenation algorithm was implemented to smoothly string together the diphones in the sequence specified by the G2P component.
On a scale of 1 to 5, the speech synthesised when using the diphone database of manually extracted diphones concatenated by the TD-PSOLA algorithm was scored 2.57 for naturalness, 2.72 for clarity, and most important of all, 3.06 for Intelligibility by evaluators. These scores were higher than those obtained when using the professionally recorded English diphone set.
In future work, the functionality of the Text Normalisation component can be expanded upon to handle more NSWs. More diphones can be recorded and extracted so that greater coverage of the language is achieved. The Diphone Concatenation algorithm can also be revisited since it wasn’t found to perform particularly well. Finally, a prosody modification component can be added which modifies the intonation and expression of the generated speech based on the what is being said and the punctuation used.
References
[1] Census of population and housing. Technical report, National Statistics Office, 2011.
[2] FITA Malta. Erdf 114 maltese text to speech synthesis.
1 http://www.festvox.org/dbs/dbs_kal.html
Student: Daniel Magro
Supervisor: Dr Claudia Borg
Co-supervisor: Dr Andrea DeMarco
Course: B.Sc. IT (Hons.) Artificial Intelligence