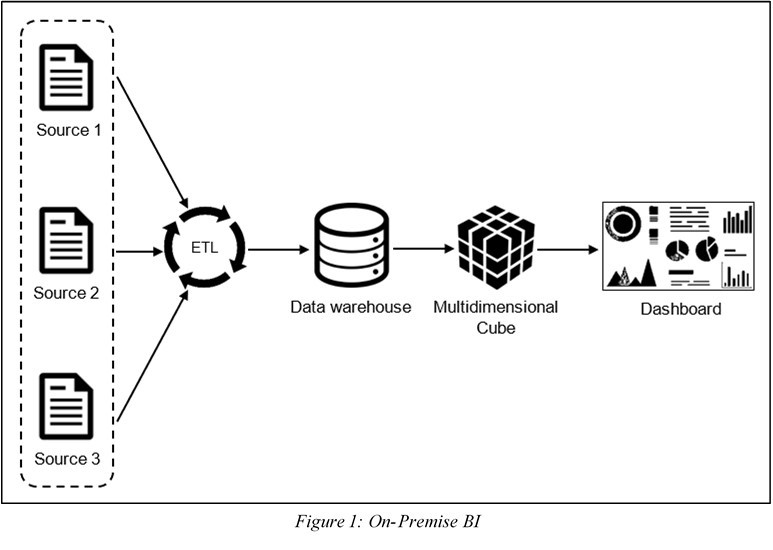
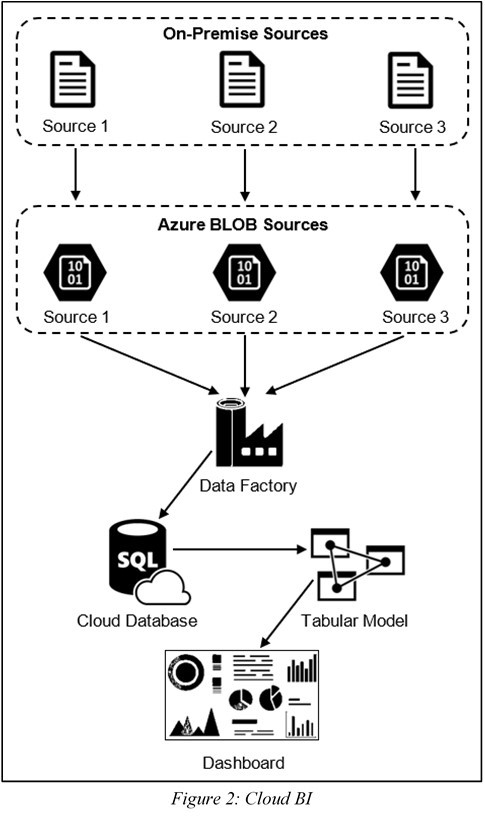
There are three main categories of BI implementations to choose from; BI On-Premise, BI Cloud, and BI Hybrid. For each category, there are different elements that affect which solution is most suitable. In this study, different characteristics of a business were identified as factors which might affect the decision of which BI implementation an organisation should go for. By considering these aspects, the most suitable implementation can be chosen. A tool was developed to guide businesses on which type of BI implementation they should choose.
To achieve the main objectives of this study, a model was built for each BI architecture, to better understand the main differences between each architecture. Then, the main characteristics that should be considered to decide on the best BI implementation were established after reviewing various research papers. Moreover, a dataset was generated using a method developed by Misra and Mondal [1]. Another dataset was also generated through a questionnaire where the questions reflected the attributes to be passed through the classification algorithms. These generated datasets were added together to form one whole set. Then, the k-fold cross-validation [2] was used to split this set into different training and testing datasets. These were used to train and test the implemented decision tree and SVM algorithms [3]. From the testing sets, the accuracy of the classification algorithms was evaluated.
The overall accuracy obtained by the decision tree was 76.36%. The overall accuracy obtained by the SVM was 74.99%. Thus, in this study, if a decision tree was to be used, it is more likely that the appropriate implementation will be selected. In most cases, whenever a record was incorrectly predicted, there weren’t any two-level jumps. This means that if a testing record was labelled as On-Premise and was predicted incorrectly, the incorrectly predicted value was Hybrid BI, not Cloud BI, in most cases. This is significant because there is a much higher jump from On-Premise to Cloud when compared to On-Premise to Hybrid. The same goes for records in the testing set labelled as Cloud BI that were predicted wrongly.
References
[1] S. C. Misra and A. Mondal, “Identification of a company’s suitability for the adoption of cloud computing and modelling its corresponding Return on Investment,” Mathematical and Computer Modelling, vol. 53, no. 3-4, pp. 504-521, 2011.
[2] G. Vanwinckelen and H. Blockeel, “On Estimating Model Accuracy with Repeated Cross-Validation,” in Proceedings of the 21st Belgian Dutch Conference on Machine Learning, 2012.
[3] J. Akinsola, “Supervised Machine Learning Algorithms: Classification and Comparison,” International Journal of Computer Trends and Technology (IJCTT), vol. 48, no. 3, pp. 128-138, 2017.
Student: Francesca Camilleri
Supervisor: Dr. Lalit Garg
Course: B. Sc. IT (Hons.) Software Development