It is possible to structure a computer program as a number of concurrent tasks that execute independently, while occasionally communicating and synchronising with each other [1]. The Go language is an instance of a programming language that promotes this paradigm.
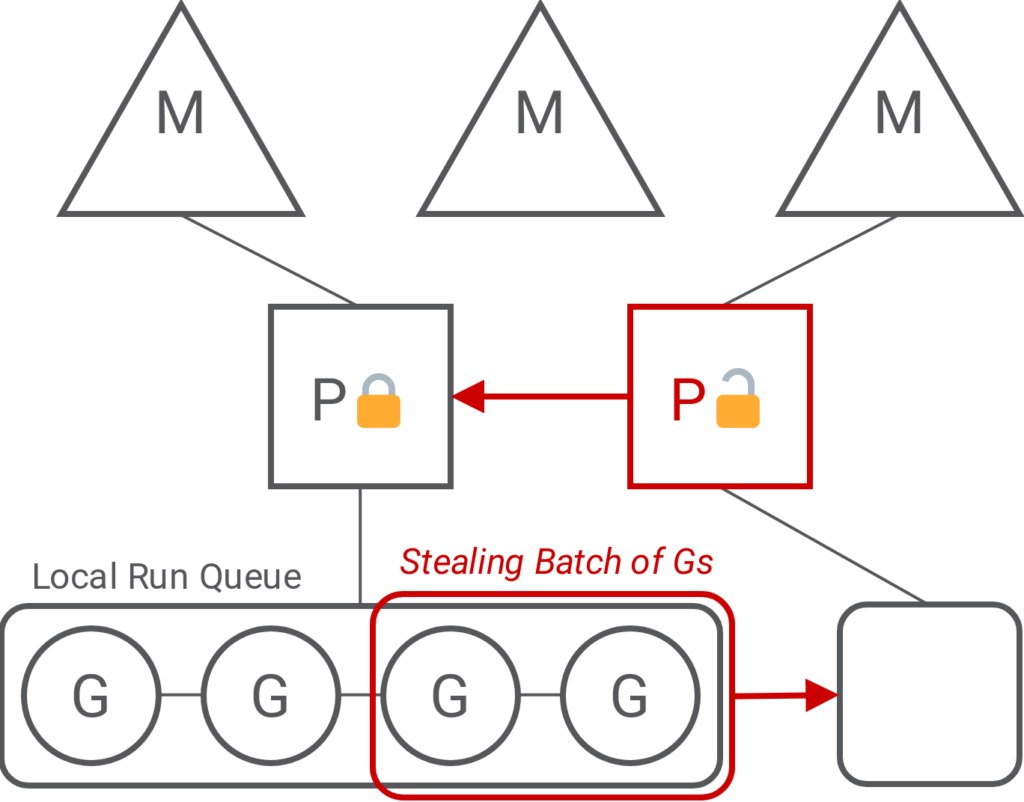
The Go scheduler multiplexes lightweight processes, referred to as Goroutines, onto the CPU cores through lower- level OS threads. These goroutines, or Gs, are managed through schedulers, referred to as Ps, as well as Ms, which are low-level OS threads which provide handles to the actual CPU cores [2].
Each P keeps a local queue of Gs, from which work is dispatched to be executed. Should a P find itself with no work, it will randomly pick and lock another P to steal half its Gs. This is how the current Go implementation makes use of its underlying scheduler structures to implement the work-stealing balancing mechanism [3].

Batching
An alternative to work-stealing is thread batching. This method dictates that tasks should be grouped and processed together, for all tasks to exploit locality through cache reuse [4].
To enable multiple batches to execute concurrently, certain criteria must be met to determine when new batches should be formed. The ideal size for the grouping and processing time differs by the type of work being done.
Larger batches mean that a processor has more tasks at hand, with potentially better cache usage, but this reduces parallelism. Longer processing times mean that tasks can be processed for longer with more cache hits, but this could lead to starvation for other batches.
This study took a constant value as the batch size limit, along with a global batch queue where all batches are shared among Ps.
Results
A cache reuse benchmark [5] which evaluates performance for workloads with differing granularities, displayed a performance improvement of up to 20%. When running the Go benchmark suite, a variety of results were observed, ranging from no improvement at all in benchmarks that are not bound by scheduler performance, to improvements of up to 69% in the more relevant instances.
The results obtained suggest that the main benefits seen are enabled through (i) the improved cache locality that is afforded by batching, and (ii) the removal of locks on Ps that were originally required for work-stealing.
Future work should focus on tuning batch size limits and yield rates to further improve performance, and optimising the distribution goroutines across batches on the basis of information gathered at compile-time and at run-time.
References
[1] T. H. Cormen, C. E. Leiserson, R. L. Rivest, and C. Stein. Introduction to algorithms. MIT press, 2009, pages 777–781.
[2] A. Clements and M. Knyszek. (Nov. 2018). Hacking.md. version d029058. Run-time Documentation, [Online]. Available: https:// golang.org/src/runtime/HACKING.md.
[3] J. B. Dogan. (Jul. 2017). Go’s work-stealing scheduler, [Online]. Available: https://rakyll.org/scheduler/.
[4] K. Vella, “A summary of research in system software and concurrency at the university of malta: Multithreading,” in Proceedings of CSAW03, 2003, p. 116. [5] K. Debattista, K. Vella, and J. Cordina, “Cache-affinity scheduling for fine grain multithreading, ”Communicating Process Architectures, pp. 135–146, 2002.
Student: Tharen Abela
Supervisor: Dr Kevin Vella
Course: B.Sc. (Hons.) Computing Science