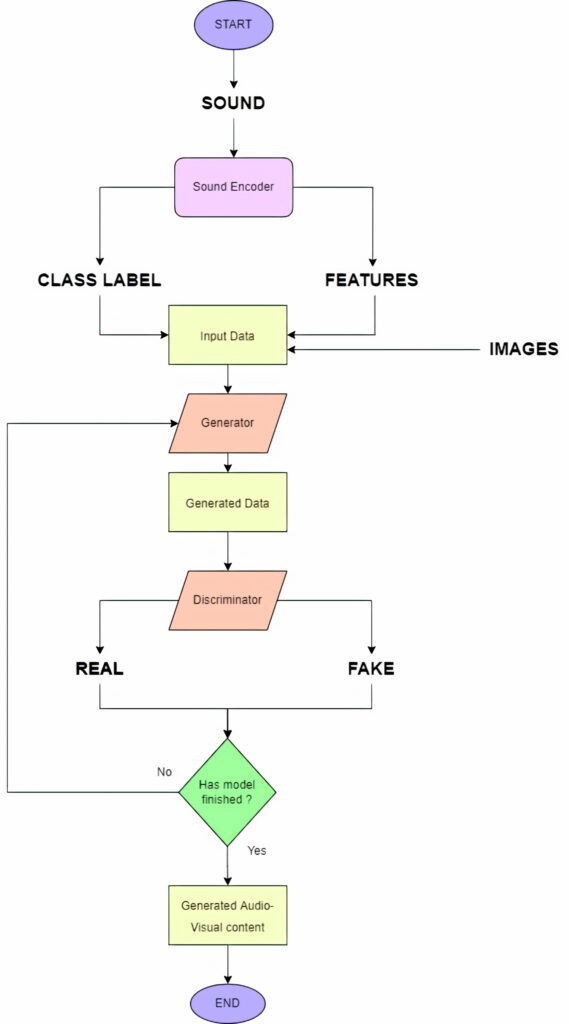
This work pursuits the prospect of cross-modal generation in computational creativity. The method employed was that of developing a specific type of AI model that is capable of generating many illustrations in the form of a moving visual based on the music provided. This allows for the creation of unique and singular pieces of the audio-visual artform.
The AI model developed is based on a Generative Adversarial Network (GAN). This model pits two networks against each other with one network trying to generate data that can pass off as real, while the other network tries to discriminate whether that data is real or not. This is integral for the reason that in this way the AI model is able to generate realistic content similar to what a real person can produce or possibly better. Furthermore, this model strays from conventional GAN models by having the ability to take sound as an input and then generate a moving art piece based on the elements of the sound provided.
The model primarily syncs pitch, volume and tempo with the image such that these features control all of the textures, shapes and objects and also control the movement between the frames.
The network mainly competes till convergence is reached, this meaning that at a point the generative network improves so much that the discriminative network is not able to tell the difference between real and fake. Hence if the model continues to compete past this point the quality of the content may drop. The system developed was tested for its ability, veracity and ingenuity with satisfactory results. The main issue is the time it takes to generate, this can be attributed to computational power and the size of the training data.

Student: Yran Riahi
Course: B.Sc. IT (Hons.) Artificial Intelligence
Supervisor: Dr Vanessa Camilleri