In the work presented by this project, the Wav2Vec 2.0 neural network architecture is fine-tuned and applied for Maltese Automatic Speech Recognition (ASR). By 2012 the Maltese language was said to be the native tongue for 520,000 native speakers. This quantitative limitation creates a number of difficulties when working on technical innovations for the language, hence its low-resource classification.
As part of this project, a novel speech corpus consisting of Maltese Parliamentary excerpts is collected and labelled. For a total of 2 hours and 30 minutes, speeches for twenty-three male and three female Parliamentary members were utilised. Together with other available Maltese corpora, including subsets from the MASRI and CommonVoice projects, a dataset totalling 50 hours is amalgamated. Studies also show that the use of additional data from auxiliary languages improves training performance. For this reason, a subset from the English Librispeech corpus is also used for further experimentation.
Before 2016 supervised machine learning methods, which heavily rely on using vast quantities of labelled data for their training, dominated the ASR field. Recently, self-supervision, a method which uses unlabelled data for pre-training a model, has been popularised in various AI fields, including speech systems. These methods can leverage unlabelled data which is much more available, even for low-resource languages.
Wav2Vec 2.0 is presented as an end-to-end ASR system able to learn speech representations from massive amounts of unlabelled data during pre-training. These Wav2Vec representations are then used to a match audio samples to their specific linguistic representation in a process called fine-tuning. Moreover, a multi-lingual approach, coined as XLSR, has been developed allowing Wav2Vec 2.0 to learn cross-lingual speech representations from a varied pre-training dataset.
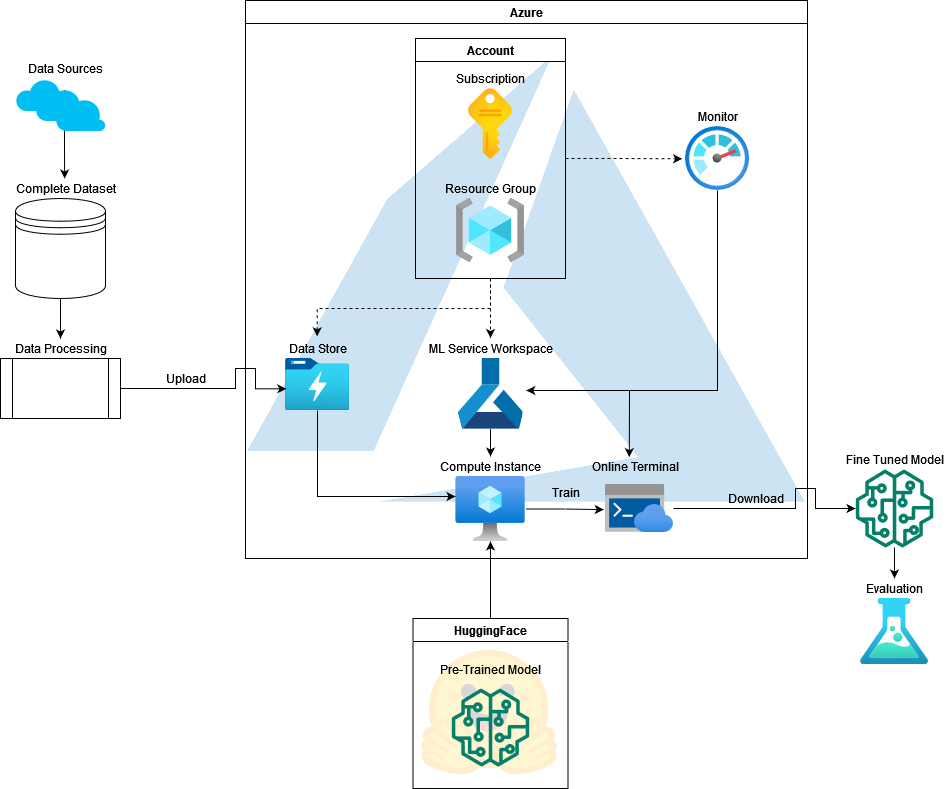
This project uses a pre-trained XLSR model and conducts various experiments with the collected Maltese and English dataset. The Wav2Vec 2.0 system supports its applicability for low-resource settings by using splits of 10 minutes, 1 hour, 10 hours, and, 100 hours. The Maltese dataset is therefore split into seven subsets: 10 minutes, 30 minutes, 1 hour, 5 hours, 10 hours, 20 hours, and 50 hours to validate these claims. The 50 hours model is then fine-tuned further on the English speech data.
The models are evaluated using the Word and Character Error Rates (WER/CER). Using more data has proven that model performance scales with data quantity, although not linearly. The best monolingual model has achieved 15.62% WER and 4.59% CER. Further evaluation is done noting the performance of the different models on a set of varied utterances. The system is also applied to generate transcriptions for a number of Maltese speeches sourced from the web with a varying degree of success.
Student: Aiden Williams
Course: B.Sc. IT (Hons.) Artificial Intelligence
Supervisor: Dr Andrea DeMarco
Co-Supervisor: Dr Claudia Borg