Grammatical inference is the process of learning formal grammars or languages from training data. DFA Learning is a subfield of grammatical inference which deals with learning regular languages as
deterministic finite state automata (DFAs).
DFA learning has been applied to robot navigation, financial forecasting, and bioinformatics among other applications which rely on real-world data that is affected by the presence of noise. DFA learning is an NP-complete problem which is made harder when noise is present in the training data. Traditional DFA learning algorithms typically construct a highly specific tree shaped DFA called an augmented prefix-tree acceptor and repeatedly merge its states for generalisation. This is done according to some heuristic such as the evidence-driven state-merging heuristic (EDSM) which is known to be a good heuristic for this task. Unfortunately, these state-merging
algorithms suffer in the presence of noisy training data.
The current state-of-the-art DFA learning algorithms which are resistant to noise are evolutionary algorithms. Unfortunately, these techniques have been shown to have a high experimental time
complexity. Therefore, while they work well when learning small DFAs, these techniques fail to scale on larger problems due to the size of the search space. Additionally, their relatively long running time makes them impractical to evaluate over a large pool of problem instances.
In this project, we study and aim to improve upon a state-merging algorithm which is resistant to noise called Blue. Blue relaxes the state-merging condition employed in traditional state-merging
algorithms using a statistical test to prevent overfitting to the training data. While Blue* does not perform competitively against evolutionary algorithms, it follows a heuristic driven state-merging approach which allows it to scale to large DFAs. Based on our analysis, we present a new heuristic based on EDSM, which is modified to handle noisy data, and apply it within three monotonic state-merging search frameworks; windowed breadth-first search, blue-fringe, and exhaustive search.
The proposed heuristic is evaluated over a variety of problem instances consisting of target DFAs and training sets generated according to the Abbadingo One competition procedures. The
performance of our algorithms is compared to that of other state-merging algorithms over a number of DFA learning problems of varying target DFA size, training set density, and level of noise. Our implementations are also evaluated over the GECCO 2004 competition datasets which consist of a variety of problem instances with 10% noise added to the training set.
In our evaluation, we obtain considerably better results than Blue* over noisy training data. We observe an average accuracy of up to 24% higher than Blue* when learning 64-state target DFAs with training sets having up to 10% noise. Furthermore, our approaches suffer a slower degradation in accuracy as the level of noise increases. When evaluating using the GECCO 2004 competition datasets, our implementations obtain competitive results against the best performing evolutionary algorithms. This project presents a heuristic which can then be applied within a variety of state-merging frameworks to handle noisy training data.
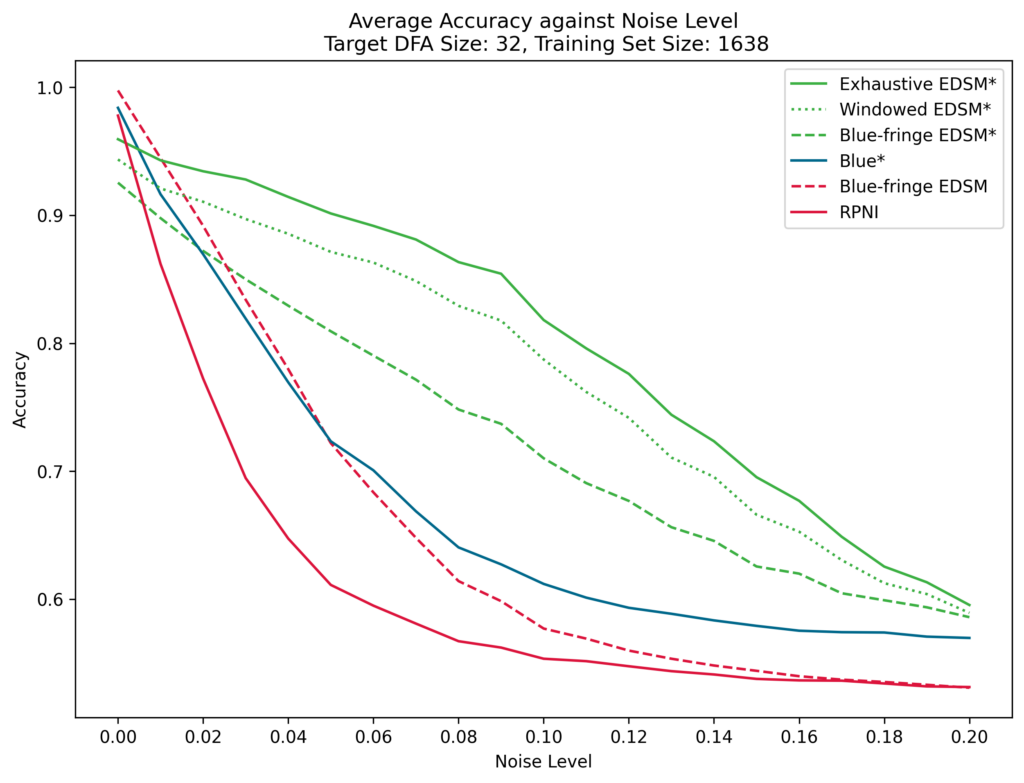
our implementations (green lines), Blue* (blue lines) and state-
merging algorithms not resistant to noise (red lines).The system’s
internal recognition process for conducting attendance
Student: Daniel Grech
Course: B.Sc. IT (Hons.) Artificial Intelligence
Supervisor: Dr Kristian Guillaumier
Co-Supervisor: Dr Colin Layfield