Visual question answering (VQA) has come a long way, especially in technologies for the benefit of persons with visual impairments. However, VQA is still incapable of answering a question in the same manner as a human being, as the ability of existing technology to (visually) interpret certain questions is limited.
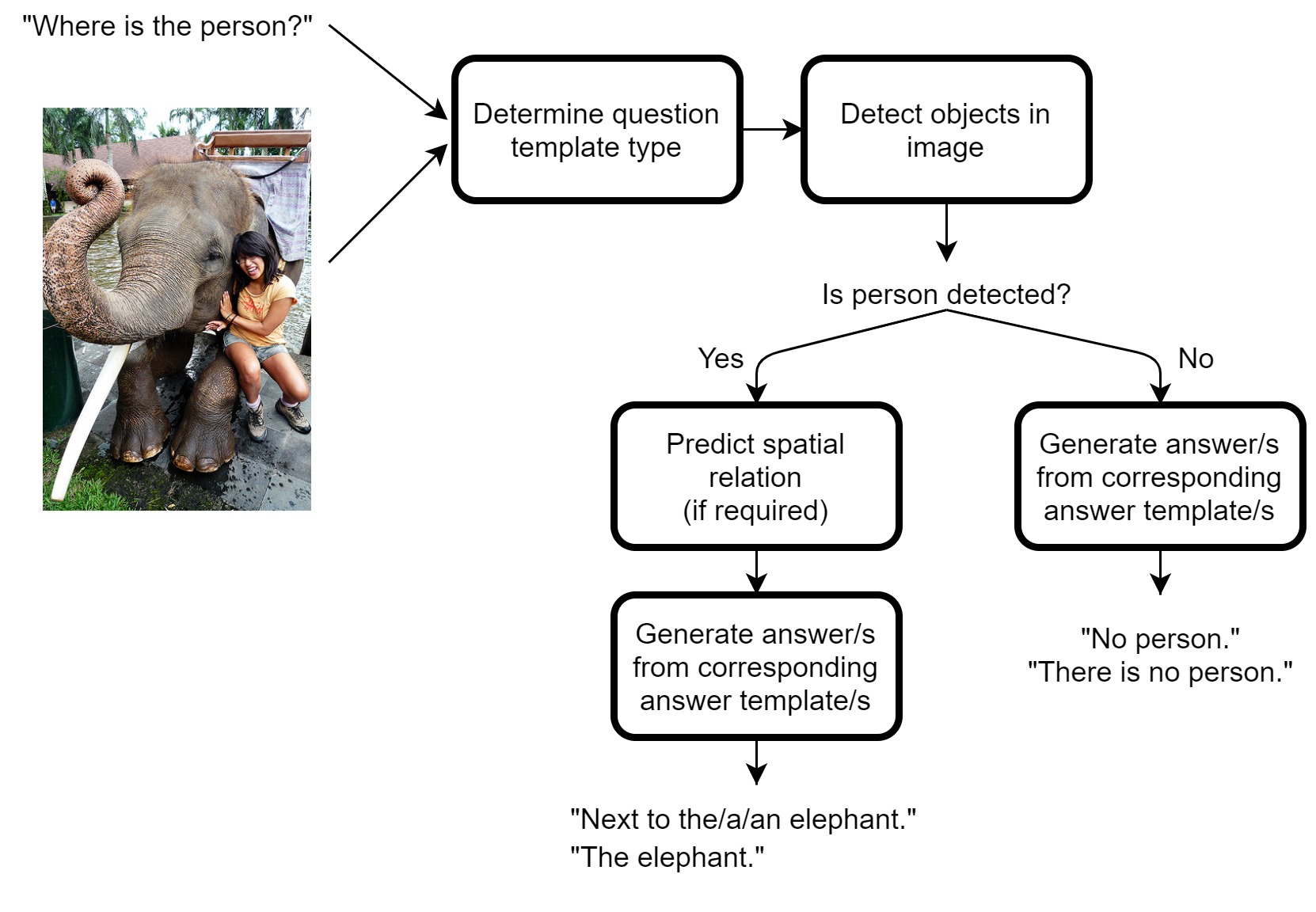
This project focused on obtaining a deeper understanding of 3 key aspects, namely: the composition of the question; how the question would be related to an available image; and how to achieve informative answers from this relationship. A dataset oriented around frequent requests made by low-sighted individuals was collated for the VQA model. Question-and-answer templates were used for the process of understanding the inputted question and the output of the resulting answer. Template gaps were filled according to the outcome of an open-source, pre-trained object-detection model, and a spatial-relation model developed for this purpose.
Models to predict spatial relations between subject-object pairs were trained and tested on a visual relations dataset (VRD). The best performing model was used in the VQA model to be able to describe relations between subjects and objects detected in images.
The VQA model was tested on the VQA dataset to evaluate the accuracy and effectiveness of the information extracted from the image, in order to predict its responses. The model succeeded in the majority of results.
Performing feature selection for the spatial-relation model might have improved the model’s output. Additionally, many of the incorrectly predicted answers were a consequence of undetected objects; had the object-detection model been trained on the images used in the VQA dataset, the experiment might have yielded better results.
Upon evaluating the results achieved, this study discusses the possibility of further work in this area. Particular attention was given towards helping reduce the daily challenges that visually impaired persons encounter in their daily lives, with the aim of helping them enjoy further independence.

References/Bibliography
[1] R. Krishna et al., “Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations”, 2016.
Course: B.Sc. (Hons.) Computing Science
Supervisor: Prof. Adrian Muscat