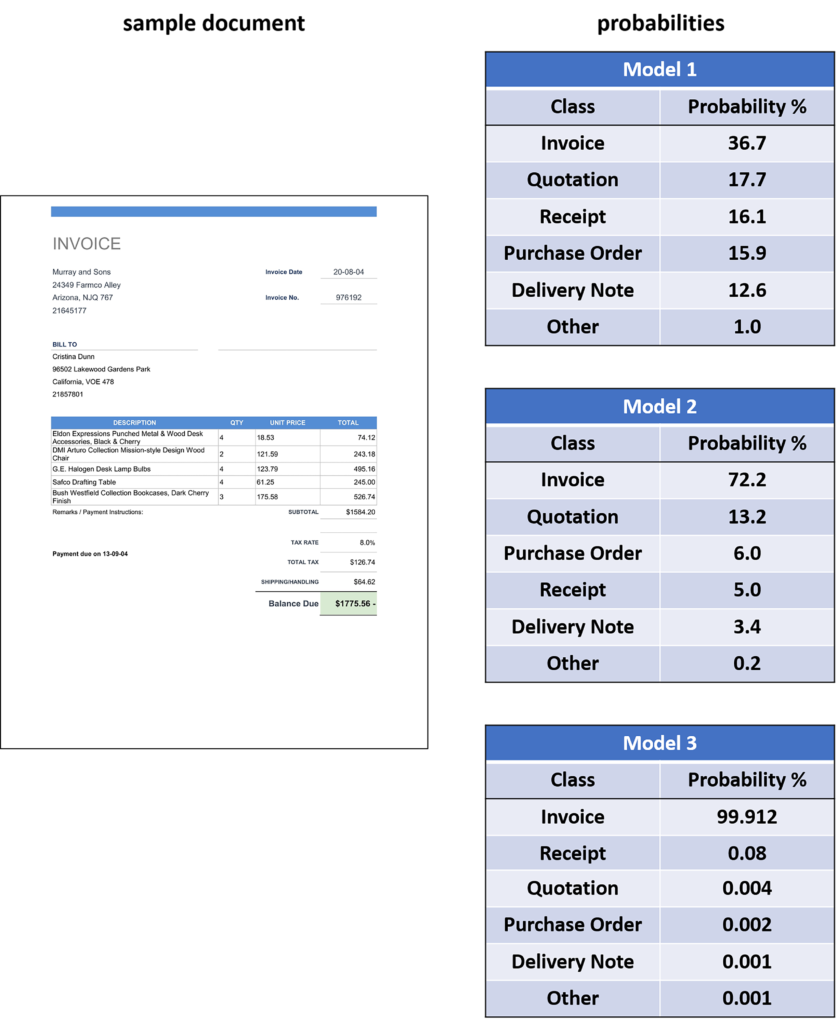
Document classification describes the task of categorizing a set of documents into two or more predefined categories. This categorization may involve a simple rule-based approach, or make use of a group of techniques usually referred to as Natural Language Processing (NLP) techniques, a subset of machine learning. This project tackles the classification of business documents into six pre-classes: invoices, receipts, delivery notes, quotations, purchase orders and others. The approach taken uses textual analysis, specifically by applying the Bag Of Words (BOW) model, meaning that each document is first pre-processed to extract its meaningful words, and the presence of these words is used to distinguish between classes, without taking into consideration their position or order and the overall visual characteristics of the documents. Three machine learning models, in increasing complexity, are proposed, implemented and compared. The models comprise a term frequency based classifier (Model 1), a TF-IDF based Multinomial Naive Bayes classifier (Model 2) and a TF-IDF based Artificial Neural Network classifier (Model 3). The Neural Network classifier obtained the highest overall classification accuracy, over 97.7%, outperforming both the frequency-based classifier and the Naïve Bayes classifier, which obtained classification accuracies of 92.2% and 91.6%, respectively. The results show how this task benefits from the implementation of deep learning, especially when the document category is not specified explicitly.
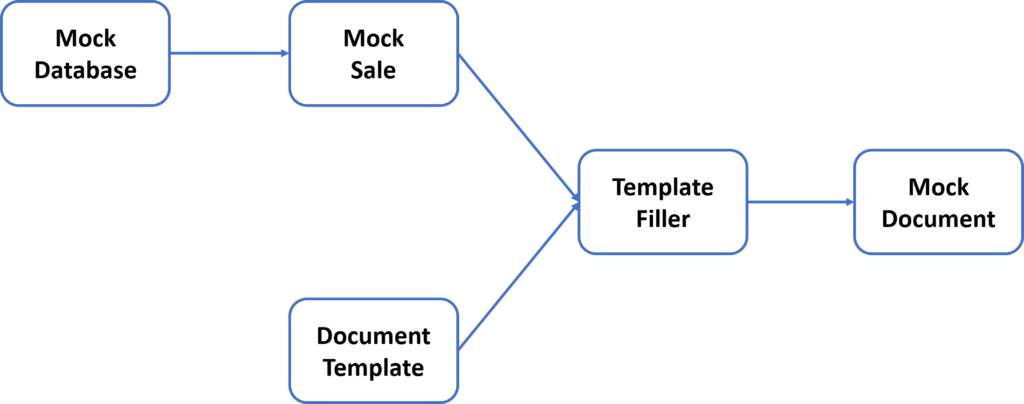
The models are trained and tested using a synthetic business document dataset, which was created as part of this project. The dataset is generated by populating document templates of the specified categories with data from a mock database. This allows for the generation of a dataset which is of sufficient size and variation for this task, whilst permitting the re-use and distribution of the dataset without raising concerns with regard to data protection.
Student: Keith Azzopardi
Supervisor: Prof. Inġ. Adrian Muscat
Co-supervisor: Dr Inġ. Gianluca Valentino
Course: B.Sc. (Hons.) Computer Engineering