One of the major challenges encountered by law enforcement entities is the prioritisation and rostering of resources, with a view to maximise the chances of being equipped with the right resources at the right place, and at the right time.
This research proposes a hybrid machine learning technology that uses a set of customised web crawlers to gather data on a daily basis from newspaper articles. Articles that deal with criminal offences would be identified, analysed and their inherent details extracted using natural language processing (NLP) technology. Articles from different sources are converged using a standardised format that allows the details of the crime (such as nature of the crime, location, time, criminal, etc.) to be accessed easily. Related data, such as population, literacy etc. are also extracted from other sources using dedicated crawlers and cross-referenced with the events related to the actual crime. Web crawling is automated using a special bot designed to initiate the crawling processes regularly.
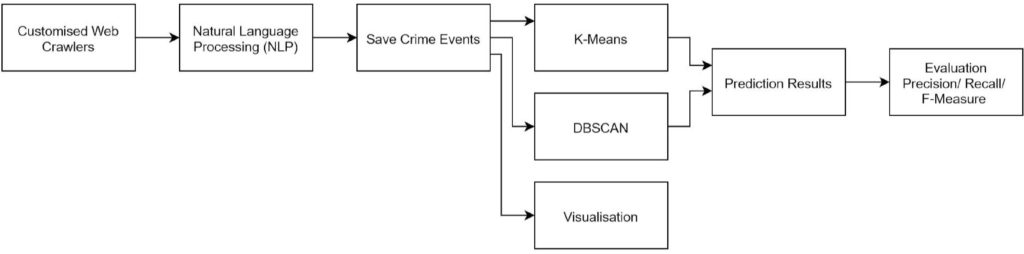
This study proposes a visualisation engine that would allow users to quickly and effectively browse the criminal- event database using a feature-rich search engine that would enable specific parameters to be easily identified and depicted. Various representations of the resultin data (such as geographical heat maps, graphs, calendar heat maps, etc.) are possible.
Previous research in similar areas has utilised various machine learning techniques with varying success rates. This research aims to study the effectiveness of k-means and DBSCAN-based technologies [1] when applied to crime prediction. While k-means uses a purely statistical past-data based model to attempt to predict the incidence of crime, DBSCAN uses clustering techniques, which could include other datasets in addition to past criminal event data.
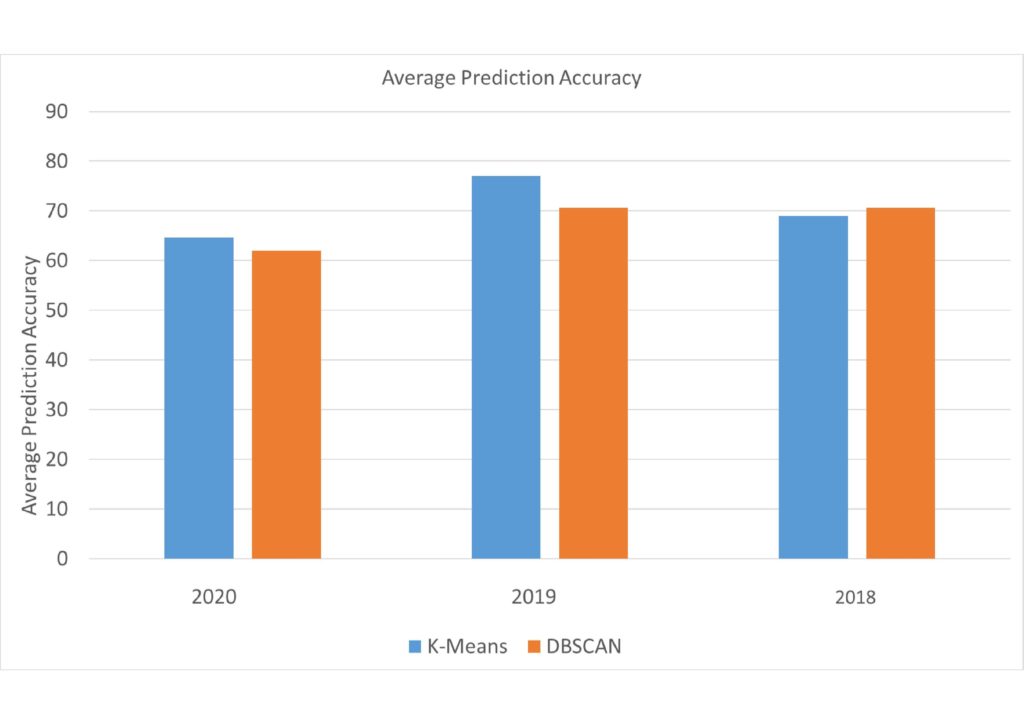
Various data has been used to evaluate the performance of the proposed technology ‒ with encouraging results. The precision / recall / F-measure technique used in previous studies [2], [3], has been utilised to compute the accuracy of both techniques. Moreover, geographically distant areas (Malta and Boston), where used to evaluate different crime patterns. Although the large number of possible prediction configurations make it very difficult to cover all the possible scenarios, both techniques performed quite well. In particular, the k-means technique proved to be slightly more accurate in predicting recurring crimes.
References/Bibliography:
[1] Baboo, S. Santhosh. “An enhanced algorithm to predict a future crime using data mining.” Int J Comput Appl 975: 8887 (2011).
[2] Iqbal, Rizwan, et al. “An experimental study of classification algorithms for crime prediction.” Indian Journal of Science and Technology 6.3: 4219-4225 (2013).
[3] Almanie, Tahani, Rsha Mirza, and Elizabeth Lor. “Crime prediction based on crime types and using spatial and temporal criminal hotspots.” arXiv preprint arXiv:1508.02050 (2015).
Student: Janica Spiteri
Course: B.Sc. IT (Hons.) Software Development
Supervisor: Dr. John Abela
Co-supervisor: Dr. Peter Albert Xuereb