In today’s advancing technology, the use of the internet is growing day by day. Hence, has become more important than ever that internet users acquire the tools to help them process the huge amounts of data on the Web. This brings about the need for recommender systems to suggest items that would be of possible interest to the individual users. This research project focused on the task of recommending films to users through machine learning algorithms, rather than methods like Collaborative Filtering And Content Based Filtering [1].
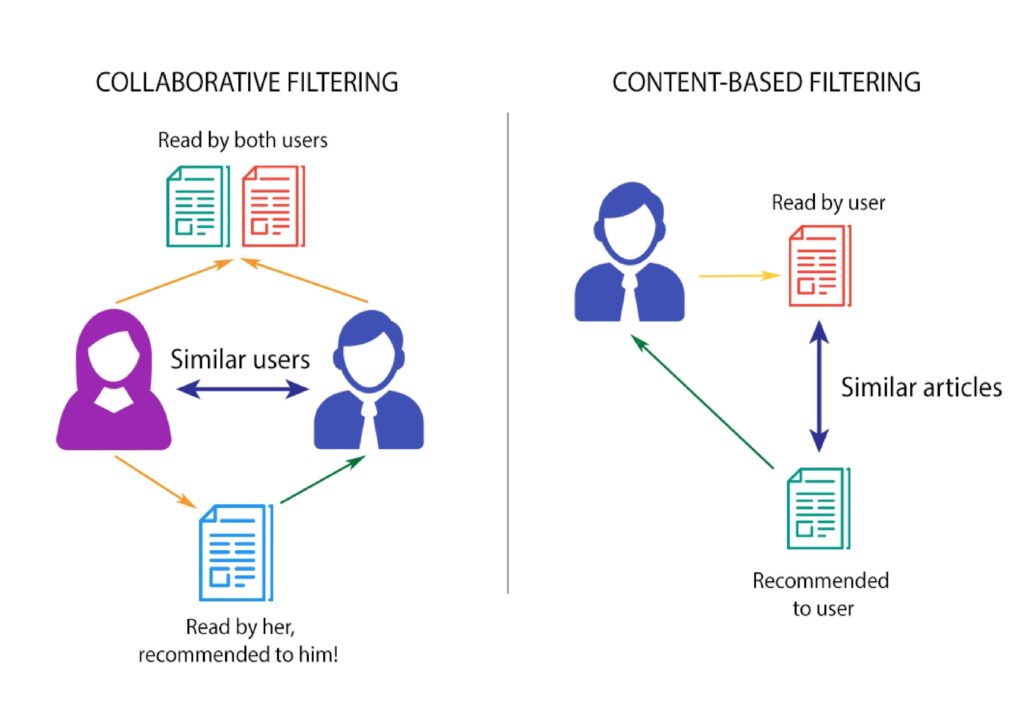
The two most popular types of recommender systems are content-based and collaborative filtering. These methods are implemented in different scenarios of recommendation, where each method is implemented differently to be compatible with the corresponding system. It is to be noted that these methods also have their drawbacks. Content-based filtering operates by recommending an item that is similar to an item that the user has already rated. If the item would not contain enough information, or if the user would not have rated any items, the recommendation would be inaccurate [1]. Moreover, collaborative filtering (CF) is based on the user’s historical preference on a set of items. It uses rating information from all other users to provide predictions for user-item interactions [2]. One of the disadvantage of this method is that it suffers from the cold-start problem, which is a start-up issue that could occur in this context when a new user and/or item would be entered without any ratings, and the recommender system would not have enough data to make any reasonable inferences [3].
The above-mentioned difficulty provided the main motivation for utilising machine learning (ML) algorithms to recommend films for the purpose of this project. ML algorithms are applicable to all kinds of data and could be employed without the need to custom-build the algorithm for the particular scenario. This study is based on determining whether using various ML algorithms would lead to better rating results when compared to the use of collaborative or content-based filtering. ML models could achieve better results because the model could be trained by using more attributes (features) about the item (i.e. a film, in this case) and the user. For example, in the case of users, one could add age, location and occupation, whereas for the item one could add the actors appearing in the film or the film genre. This information enhances the recommender system because the ML algorithm is also considering these attributes, whereas other algorithms, such as collaborative filtering, are not equipped to include them.
The results of this research were evaluated by using mean absolute error (MAE), by measuring the errors between paired observations and comparing them to other researches. The research led that, when training a model using the whole dataset, the results were not as quite as good as to other research. Moreover, the ML model was implemented to focus on each individual film rather than all the films at once, and an ML model was trained on the dataset of each film, thus generating better results. This outcome led to the conclusion that an ML model offers better recommendations when trained on individual items.
References/Bibliography:
[1] Anonymous “Cold start (recommender systems),” 2020. Available: https://en.wikipedia.org/w/index.php?title=Cold_start_ (recommender_systems)&oldid=973940047.
[2] B. Rocca. (-06-12T07:48:22.390Z). Introduction to recommender systems. Available: https://towardsdatascience.com/ introduction-to-recommender-systems-6c66cf15ada.
[3] N. Sharma. (-02-05T16:02:43.917Z). Recommender Systems with Python — Part I: Content-Based Filtering. Available: https:// heartbeat.fritz.ai/recommender-systems-with-python-part-i-content-based- filtering-5df4940bd831.
[4] S. Doshi. (-02-20T16:32:35.531Z). Brief on Recommender Systems.
Student: Steve Spiteri
Course: B.Sc. IT (Hons.) Software Development
Supervisor: Dr. Clyde Meli
Co-supervisor: Dr. John Abela