There has been an increase in speech-recognition software used in many devices. This software was initially introduced to the public mostly through smartphones. As technology is constantly improving, speech recognition software is found on different devices and household appliances, such as televisions and even refrigerators. As people are using speech-to-text software more frequently, this form of computer interaction is becoming the norm. Hence, inaccuracies such as words misunderstood for others, may cause certain difficulties in the future.
The project evaluated and compared the most relevant models, to establish which would be best adopted in different circumstances. This study sought to give a clearer picture of how these devices and appliances work, since speech recognition software seems to be becoming an attractive form of computer interaction.
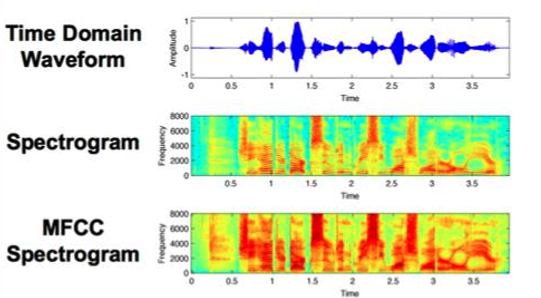
The project set out to delineate different topics, such as sound and preprocessed sound recordings. It then focused on feature extraction techniques, for the purposes of retrieving key characteristics of sound waves that could be used at the speech recognition stage. This could be achieved by applying mel-frequency cepstral coefficients (MFCC), which could be presented graphically by using a spectrogram (see Figure 2).
Lastly, the data from the feature extraction process was fed into the different models. Three models, namely: the hidden Markov model, a convolutional neural network and the dynamic time warping algorithm, were selected and compared using the same datasets. The results were then evaluated using accuracy and running time.

References/Bibliography
[1] Bhushan, C., 2016. Speech Recognition Using Artificial Neural Network – A Review. [online] Iieng.org. Available at:
[2] Smales, M., 2019. Sound recording visualised in different formats. [image] Available at:
Course: B.Sc. IT (Hons.) Software Development
Supervisor: Dr Colin Layfield
Co-supervisor: Prof. John M. Abela