Grammatical inference is the task of finding a formal grammar or class description from a training set. This project is particularly concerned with DFA learning, which involves finding a minimum-state DFA (deterministic finite automaton) from strings that might or might not belong to a regular language. This is an NP-hard problem which has many practical applications including natural language processing, bioinformatics, genetic sequencing, robotics, software verification, and data mining.
A significant obstacle encountered by students, academics, and practitioners, especially if unfamiliar with this area of research, is having to undertake the non-trivial task of implementing complex data structures and algorithms from scratch. While a number of publicly available DFA-learning toolkits do exist, they tend to have some important shortcomings. More specifically, their readability, performance, documentation, and extensibility could be improved further.
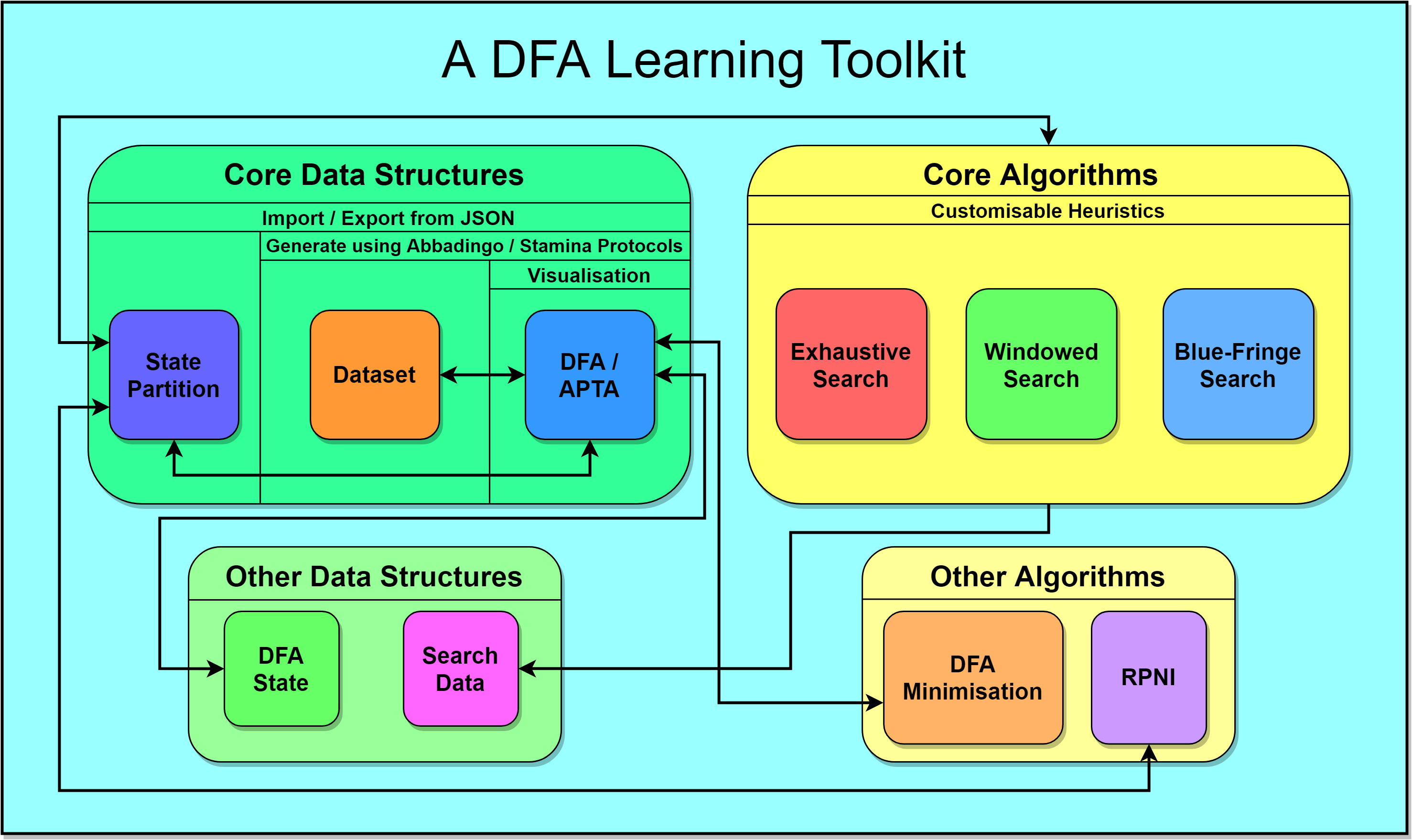
This project was concerned with developing a DFA-learning framework that is modular, efficient, properly documented, and sought to address a number of shortcomings in existing frameworks. The framework was implemented in Go code, which offers the advantage of having excellent runtime performance characteristics, as well as having a much gentler learning curve when compared to other high-performance languages. By design, Go is also very user-friendly.
The developed toolkit features efficient and properly tested implementations of several data structures, state-merging algorithms, as well as state-of-the-art heuristics. It is particularly significant that these implementations were designed to be user-customisable and extensible. The framework also allows users to generate target DFAs and datasets using both the Abbadingo and the Stamina protocols. This is a very important feature, as it allows both students and researchers to experiment with different techniques on large pools of problem instances. To further support experimentation, the framework developed for the toolkit also has the ability to persist instances of the most important data structures and visualisation tools.
The practicality of this toolkit was duly evaluated by implementing a number of higher-order DFA-learning algorithms to emulate real-world uses of the related framework. A second version of the said framework was implemented in Rust, which is limited to performance critical portions of the main framework. Since Rust is generally considered to be a high-performance language, while having a much steeper learning curve than Go, working with Rust facilitated the evaluation of Go in terms of whether this code offered the right balance between runtime performance and readability.
Course: B.Sc. IT (Hons.) Artificial Intelligence
Supervisor: Dr Kristian Guillaumier