This project attempts to contribute to audio-forensic procedures by providing a system that would process and check audio files for their authenticity, through various methods. In order to achieve this, it would be necessary to build a collection of tools and techniques, as creating a single tool would result in great difficulty adapting the tool to all the situations/scenarios encountered in the field of audio forensics.
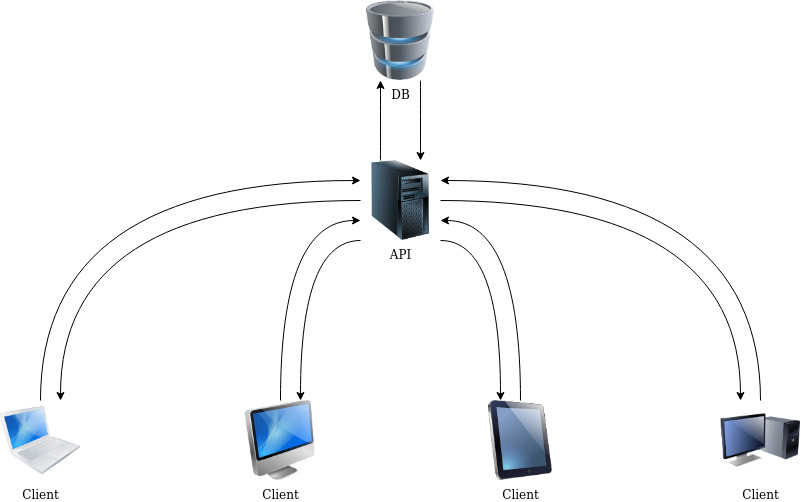
In its original version, the project is a web-based system that would allow the forensics expert to upload and analyse audio files. However, provisions were put in place through the construction of an application programming interface (API), to allow other types of clients to access this system such as mobile, web and desktop applications simultaneously (as depicted in Figure 1). In addition to this, the API would allow clients to run analysis tasks on the data available.
The system accepts multiple file formats as input, such as FLAC, AAC, WAV, MP3, etc., with the multiple audio files being supported by the Librosa library. This would allow the importation of multiple audio file formats into a standard format. It is recommended that source audio files be stored as WAV or some other lossless file format, to ensure the preservation of details that could otherwise be lost when using lossy file formats.
Furthermore, in order to achieve the desired functionality, several libraries, frameworks and tools were used. Among these were: Django, Django Rest Framework, React, SciPy, Numpy, MathPlotLib and Librosa. The Django and Django Rest Framework were used to construct the API needed for the front end (which was built using the React and Material-UI libraries, among others). SciPy, Numpy, MathPlotLib and Librosa are used to load, process and output results of analysis done on audio files.
The available methods fall into two categories: container-based analysis and content-based analysis. Container-based analysis examines the properties of the file (i.e., date and time of creation/modification) whereas content-based analysis examines the actual content of the file (i.e., the waveform). Authenticity could be guaranteed by: searching for a discontinuity in a feature hidden within the waveform (e.g., electric network frequency); checking if different microphones recorded the audio file (e.g., microphone signature analysis); checking if different environments were used to record the audio file (e.g., environmental signature analysis); checking if different speakers recorded the audio (e.g. speaker identification); and checking for discrepancies within the properties of the file (i.e., container analysis).
The system pays particular attention to the integrity of data through file hashes, which are random strings of numbers and letters that represent a whole file. Any change in the file would result in a file hash that would be completely different from the previous one. The original file hash would be recorded immediately upon upload, safeguarding against any tampering of data after this point. In addition to this, the system also places importance upon the access levels for users, meaning that each user should only be able to access the parts of the system they may view, and not others.
Course: B.Sc. IT (Hons.) Software Development
Supervisor: Dr Joseph G. Vella