The digital footprint defines a person’s digital presence, such as the user’s activity on social media platforms. These platforms are becoming increasingly more popular and are growing in number. Social media sites, allow users to express opinions, tastes, and emotions. On the basis of this information, the study attempts to predict and determine a user’s state of mind, with a view to assessing whether they might require help in maintaining their psychological well-being. This could be achieved by analysing a user’s posts and comments, paying particular attention to any defining traits in the user’s language that could suggest that the user might be – or is at risk of – experiencing a psychological condition.
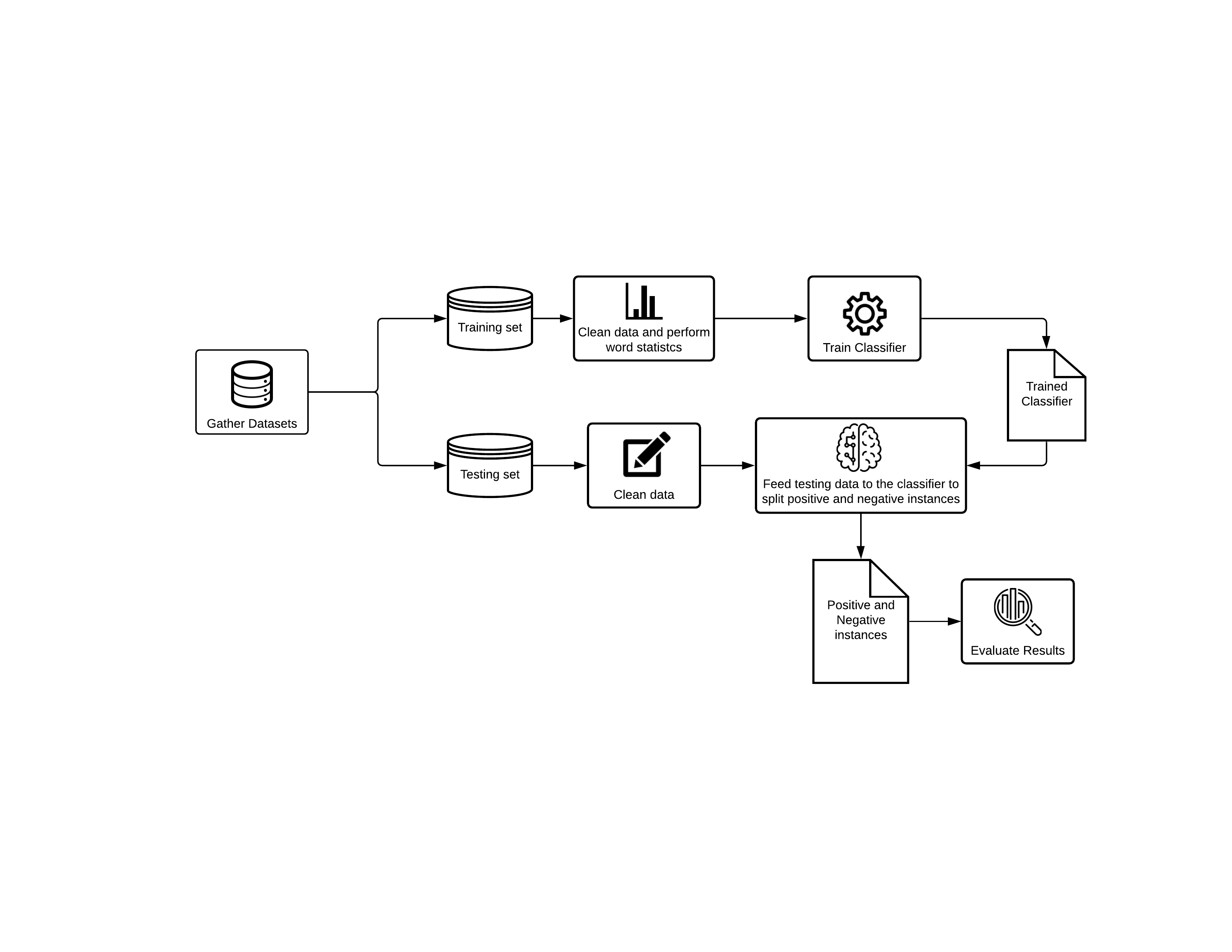
For this project, a dataset from the social networking site (SNS) Reddit was used. This platform was chosen for its quality of allowing users to express themselves freely and informally. This is particularly relevant, as a person’s true character is most evident when they can express their true self.
The data which was used throughout this project consisted of Reddit posts (including comments) collected from 1707 users. There was a varying number of posts from one user to another, and the total of the entire dataset amounted to 1, 076, 582 different posts. Approximately 8.4% of these users appeared to be depressed, whilst 91.6% of the users were control users who did not suffer from depression. Users were classified as being depressed if they explicitly mentioned that they had been diagnosed with depression.
This study sought to learn certain traits in the language used by users actually suffering from depression, so as to determine whether other users would indeed be experiencing depression or at risk of depression. These traits include the use of specific words, the length of the Reddit of the user’s posts, and the particular use of certain punctuation, such as repeated exclamation marks (e.g., ‘!!!’), among many others. Multiple techniques were tested, in order to identify the best approach for reaching the aims and objectives. Amongst the models that were considered are: support-vector machines (SVMs), neural networks (NNs) and random forest classifiers (RFCs).
The most efficient way to predict depression could be determined depending on the results achieved in this study. This method could then be applied to other social media platforms to establish whether the user might be at risk of depression or already suffering from depression. The user could then be notified of the risk that they might be facing and recommending what could be done to treat depression to regain mental well-being and a better quality of life.
Course: B.Sc. IT (Hons.) Artificial Intelligence
Supervisor: Dr Lalit Garg