Big sporting events are reported in real time by many news outlets in the form of minute-by-minute updates. Many news outlets also issue a news summary of the event immediately after the end of the event. This is generally a time-consuming task, and the journalists would be always under pressure to be among the first to issue their report at the end of the match, in order to publish the articles at a point when the level of interest would be at its peak.
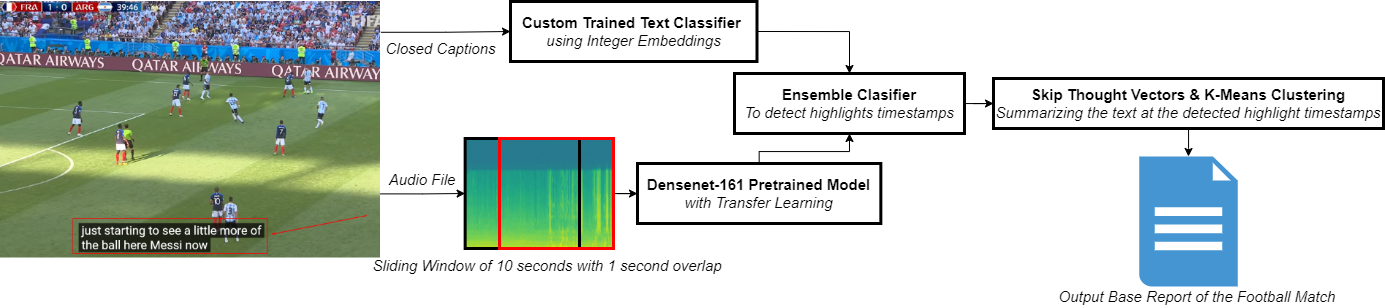
This project proposes a method for detecting highlights from a football match automatically, by using both audio and text features that have been extracted from the commentary. Once the highlights would be detected, the system would then create a textual summary of these highlights, thus facilitating the production process of news articles based on sports reporting.
The dataset used comprises some of the best FIFA World Cup matches published on YouTube. This dataset made it possible to extract the audio from each video, and the text was automatically generated through automatic closed captioning (CC). The project entailed creating a corpus of 14 matches, totalling 23.5 hours. Previously available corpora were either only text-based (such as minute-by-minute reports) or focused on features that were aimed at classifying game outcomes. In order to use the audio files as input to a classifier, the task at hand required producing spectrograms, through which any features identified could be analysed. The data is split into 70% training set and 30% test set.
In order to build the system, two separate classifiers were trained: one for the audio and one for the text. The audio classifier was based on a DenseNet architecture, whereas the text classifier was based on a 1D convolutional neural network (CNN) architecture. Once the individual components were trained, a further ensemble classifier was trained to determine the correct level of confidence that should be present in the audio and text classifiers – outputting a final classification for the corresponding timestamp. Finally, once the highlights were classified, the system used the text from the relevant detected timestamps as highlights to produce a summary report.
The audio and text classifiers were evaluated as separate components, whilst the summary outputs were evaluated by comparing them to gold-standard reports from various sports sites. In future work, such a system could also include video analysis, thus providing a richer feature system to detect and report highlights. The same approach could also be applied to different types of sporting events.
Course: B.Sc. IT (Hons.) Artificial Intelligence
Supervisor: Dr Claudia Borg