Sentiment analysis (SA) is a research area within the field of natural language processing (NLP) that involves extracting subjective information from text. Recently, the focus within this domain has shifted towards mining opinions and attitudes from social media postings covering a vast range of topics, including: product reviews, politics, stock markets, and investor opinions. The availability of vastly varying, sentiment-rich social media postings significantly increases the potential and importance of SA techniques.
This research focused on SemEval-2017 Task 4A English [1], a competition revolving around the classification of Twitter postings into three sentiment classes (positive, negative, neutral). This event attracted 38 teams from various universities and organisations worldwide. The aim of the research was to investigate ways to build better-performing models than those constructed by the top-ranking teams.
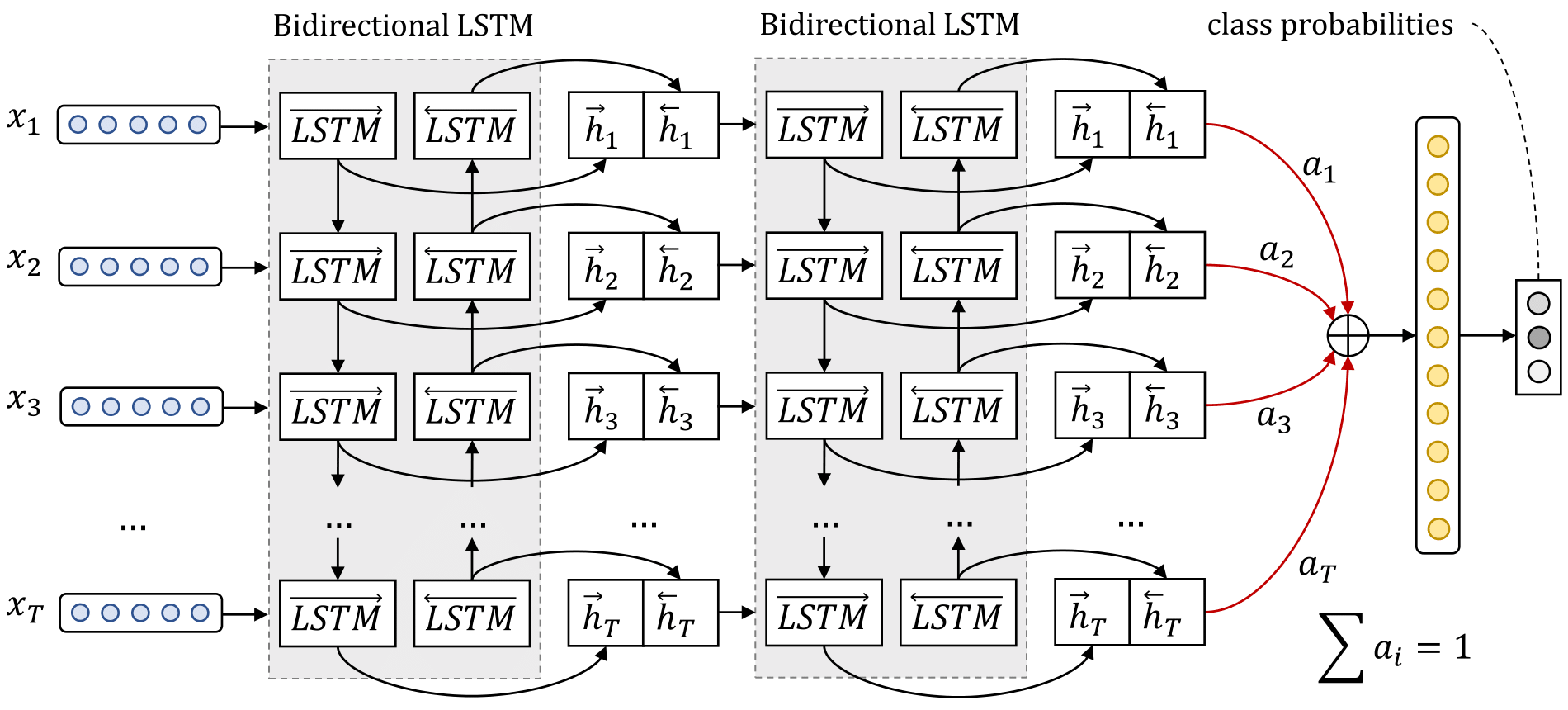
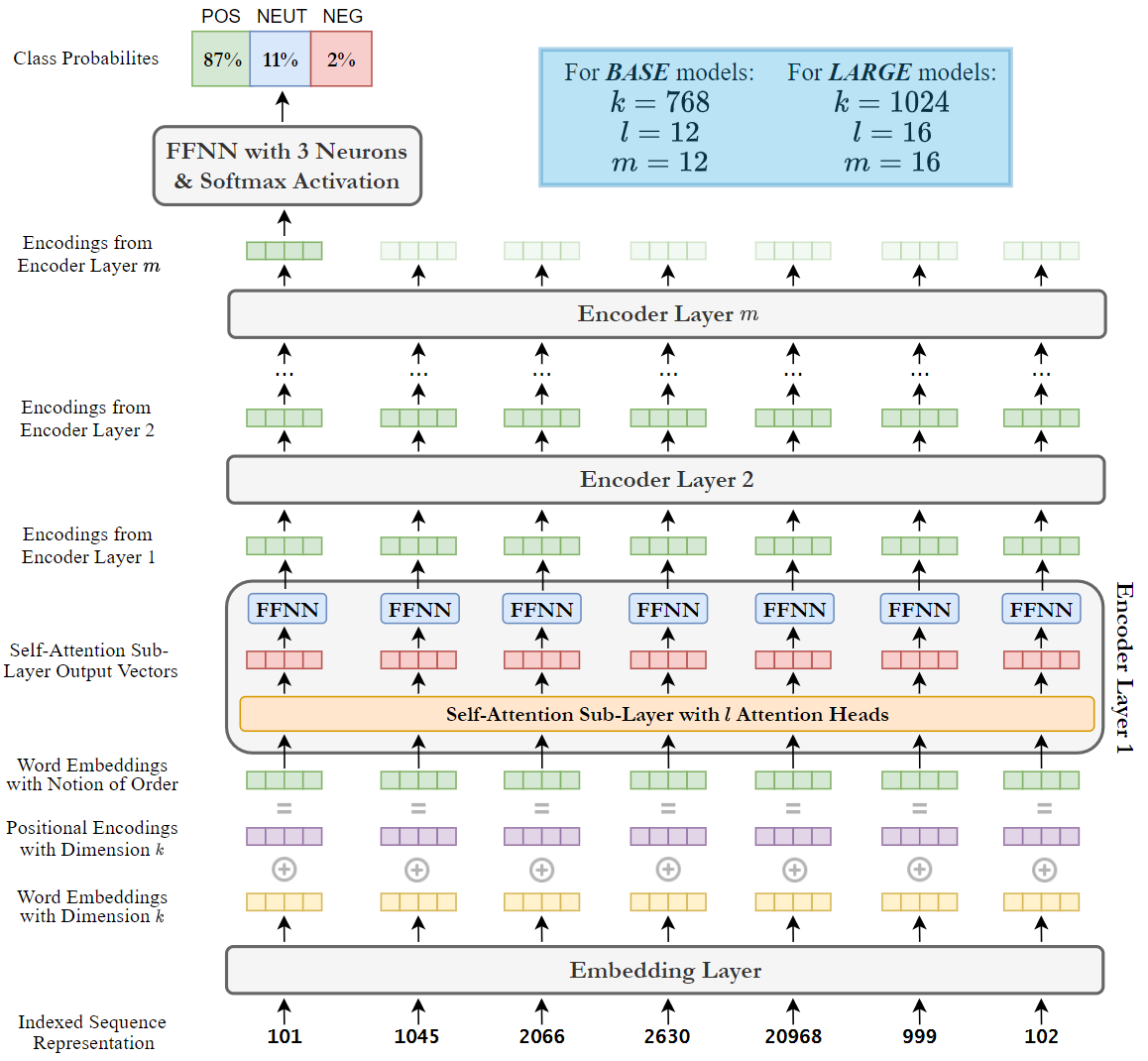
This study was carried out in two parts. The first focused on optimising the model of DataStories [2], one of the two teams that tied in first place in the SemEval-2017 competition. Their approach used deep bidirectional LSTM networks paired with an attention mechanism. The DataStories results were reproduced first, followed by the execution of a number of experiments. These included: identifying the optimal validation-set evaluation metric; checking for seed sensitivity; finding the optimal train-validation split ratio; and hyperparameter optimisation. The second part focused on training, optimising, and evaluating models incorporating the transformer encoder architecture, namely BERT and RoBERTa, using the competition data. The necessary experiments were also carried out on these models, in an attempt to improve the results. To facilitate experimentation, the systems developed in this work adopted a grid-search framework.
All developed models outperformed the original DataStories model. The configuration of the said model was optimised, thus achieving a slightly better performance. Furthermore, the BERT and RoBERTa models significantly outperformed the configurations of the DataStories model, further confirming the dominance of such models over others for various NLP tasks.
References/Bibliography
[1] S. Rosenthal, N. Farra, and P. Nakov, “SemEval-2017 Task 4: Sentiment Analysis in Twitter,” in Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), 2017, pp. 502–518, doi: 10.18653/v1/S17-2088.
[2] C. Baziotis, N. Pelekis, and C. Doulkeridis, “DataStories at SemEval-2017 Task 4: Deep LSTM with Attention for Message-level and Topic-based Sentiment Analysis,” in Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), 2017, pp. 747–754, doi: 10.18653/v1/S17-2126.
Course: B.Sc. IT (Hons.) Software Development
Supervisor: John Abela