Grammatical inference is the task of learning a formal grammar or class description from a set of training examples. This research has focused on learning regular languages represented by deterministic finite-state automata (DFA).
DFA learning is an active research area offering various applications, including pattern recognition, robotics, and speech. The issues targeted in this project consist of an unknown DFA whose alphabet is binary, similar to those used in the Abbadingo One competition. A dataset of strings was labelled by this DFA and given to the learner. The learner would then construct a hypothesis (DFA) with this dataset, the accuracy of which would be calculated using another set of strings, called the testing set. The inferred DFA must either match the target DFA exactly or reach a high degree of accuracy (≥99%).
A common and successful approach to solving this problem would be to build a maximally specific hypothesis called an augmented prefix-tree acceptor, which accepts the training data exactly. Subsequently, a heuristic, such as the Abbadingo-winning evidence-driven state-merging (EDSM) algorithm, would be used to score merges. State-merging heuristics score each possible merge in a DFA, indicating the level of the merge. The EDSM algorithm does this by comparing labels of states that are to be merged. The highest-scoring merge is performed, and this process is repeated until no more merges are possible, thus delivering the final DFA.
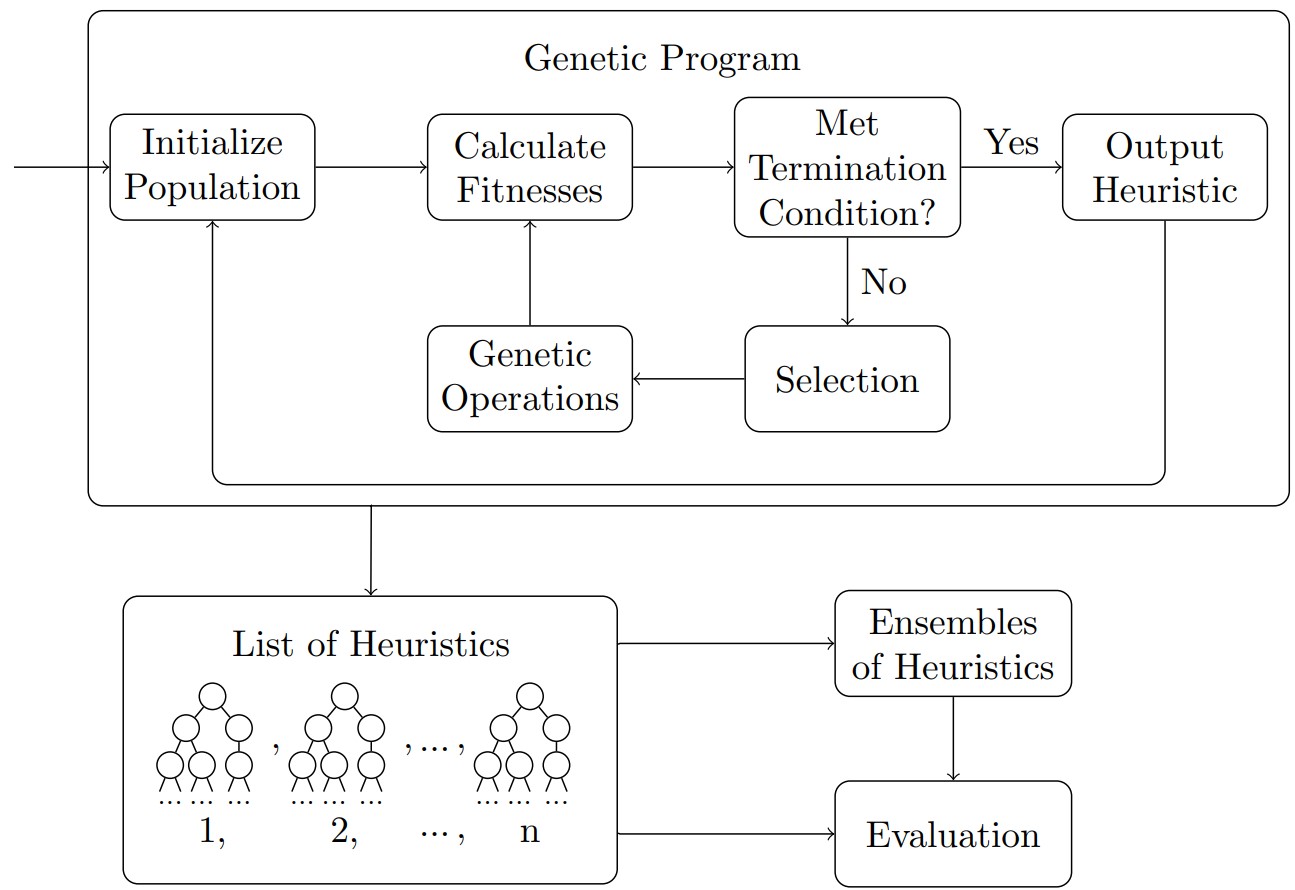
In this project, the relevant types of heuristics were developed using a genetic program (GP). A GP evolves a number of possible solutions with the aim of finding a better one. The ‘fitness’ of each heuristic is calculated by using the heuristic itself to solve a number of problem instances. Then, its fitness value would be equal to the percentage of problem instances it was able to solve.
Running the GP numerous times resulted in multiple viable state-merging heuristics. While these heuristics performed well on their own, their performance could be increased by forming an ensemble. When faced with a problem, each heuristic in the ensemble would generate a DFA using the training set. There are several methods for parsing the testing set consisting of an ensemble, with a majority vote being the most straightforward. With this approach, each string would be parsed by every DFA in the ensemble, and its label would be determined by the verdict given by the majority.
The motivation behind using an ensemble hails from the ‘no free lunch’ (NFL) theorem, which states that ‒ in general ‒ there is no single heuristic that dominates all others over all problem instances. This could be observed when using another heuristic called reduction, which ‘greedily’ chooses merges that reduce the largest number of states. While EDSM solves a higher percentage of problems, the reduction heuristic is able to solve problems that EDSM cannot.
The performance of the ensembles, and the heuristics generated by the GP, were evaluated using a number of problem instances consisting of DFAs of varying sizes. Certain heuristics generated by the GP delivered a very promising performance, exceeding that of EDSM. Furthermore, the performance of certain ensembles consisting of these heuristics was also very promising, significantly exceeding that of any stand-alone heuristic.
Course: B.Sc. IT (Hons.) Artificial Intelligence
Supervisor: Dr Kristian Guillaumier
Co-supervisor: Prof. John M. Abela