Audio-source separation is the process of breaking down a mixture of audio signals into its individual sources. This project focused on music, which meant extracting the different instruments from a recorded song. Audio-source separation could also be used to separate any type of source from an audio signal. This source could be anything from instruments, vocals, and background noise ‒ and could even be used to separate two sources of the same nature, such as two vocals.
Deep learning (DL) has been proven to produce better results over traditional approaches, such as matrix factorisation methods and local Gaussian modelling. Nowadays, the application of deep neural networks (DNNs) is the most widespread approach in achieving state-of-the-art performance. Most models explored use supervised learning techniques, more specifically convolutional neural networks (CNNs) and denoising autoencoders. Some recent advances have been using unsupervised techniques with generative adversarial network (GAN) priors. These different approaches also vary as to which signal domain they chose to work with. Some approaches of audio-source separation have used spectrogram representations of the audio signal ‒ which is a visual representation of the audio signal ‒ as an input to the DNN; others have used an end-to-end approach, which means working directly in the time-domain or directly using the waveform of the audio signal.
This project investigated how differences in the data, training and model would affect the outcome of an end-to-end model for audio-source separation. Wave-U-Net was used as the base-model approach to conduct different experiments. Wave-U-Net is a DL model that works directly on the time-domain to separate audio signals by convoluting the input repeatedly while down-sampling, and repeating this while up-sampling. Three different experiments were held in order to investigate how the data, training and the model would affect the outcome.
The first experiment investigated how the data affected the training. Wave-U-Net was run on a dataset to sample the audio in three different sample rates, namely: 44.1 kHz, 22.05 kHz and 16 kHz. The next step entailed an experiment with different optimisers and how these would affect the training time and outcome of the model. The final experiment involved different configuration iterations of the Wave-U-Net model by changing the depth of the model and removing the skip connections to establish how this would affect the model.
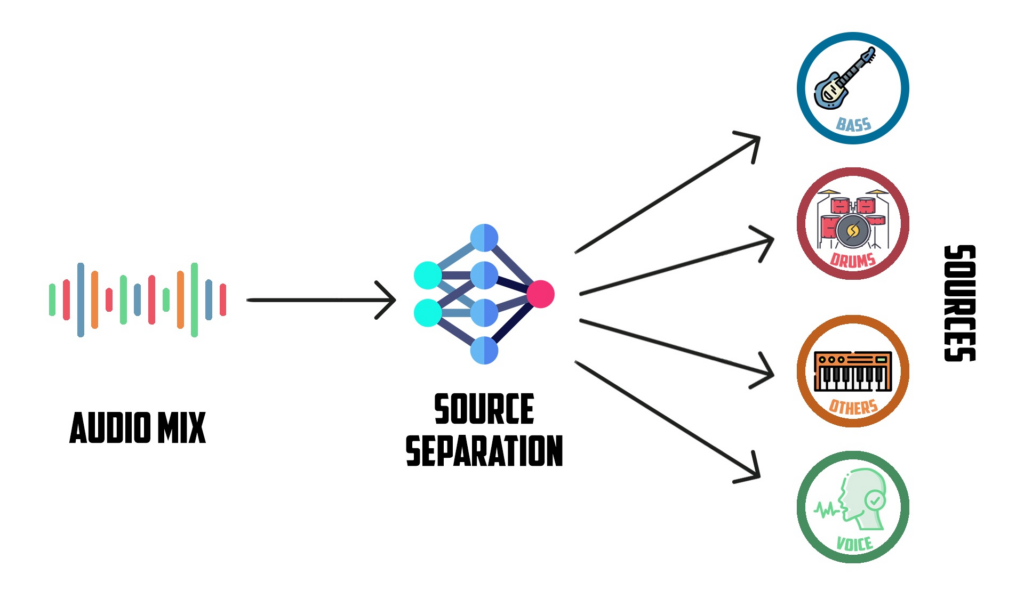
Figure 1. Diagram of the audio-source separation task
Student: Matthew Calafato
Supervisor: Dr Kristian Guillaumier