The project aimed to develop a system for autonomous drone control, with particular focus on the problem of obstacle avoidance. The successful development of such a system would be crucial for ensuring the safe and efficient deployment of drones across various industries, including search-and-rescue operations, package delivery, and infrastructure inspections.
The project sought to develop and evaluate algorithms based on Reinforcement Learning, that could enable drones to navigate safely through cluttered environments, including obstacles that are either static or moving. To achieve this, AirSim was used to simulate drone physics, and the UnReal engine was used to construct its simulated environment.
Reinforcement learning (RL) is a sub-field of machine learning (ML) that trains agents to interact with their environment in order to maximise a particular reward obtained by taking certain decisions. The process of training the agent to navigate the set environment included awarding positive rewards when it reached its target destination successfully, moving closer to its desired position after each action, and adequately overcoming an obstacle. A negative reward was given when the agent collided with an obstacle, took too long to reach its goal, or remained stationary. A training episode ended when the agent reached its target goal or collided, and the training environment was reset with randomised obstacles. Adding randomisation to obstacles helped the agent improve its ability to generalise, during training.
The agent was provided with observations that represented different states of the environment. This included depth imagery that was captured at every step using the drone’s depth sensor. This state was processed using a convolutional neural network (CNN), which extracted and learned relevant features from these images. In addition to depth imagery, the agent also received information on its current velocity, its current distance from the goal, and a history of its previous actions. These actions were passed through a traditional artificial neural network (ANN) before being flattened and combined with the processed imagery to be fed to the agent.
The framework was utilised to train a model that would complete its task effectively, using both discrete and continuous actions. To train the discrete model, two agents were deployed with the deep Q-networks (DQN) and double deep Q-networks (DDQN) algorithms, respectively. Similarly, two agents were trained using the Proximal Policy Optimization (PPO) and Deep Deterministic Policy Gradient (DDPG) algorithms for continuous models. The difference between discrete and continuous actions is that discrete actions have a finite set of possible choices, whereas continuous actions would offer an infinite set of possible choices. In the specific context of this project, the discrete model was assigned actions such as ‘move left’, ‘move right’, ‘move forward’ and ‘move backwards’, at a specific speed. On the other hand, the continuous model could control the drone’s speed and direction.
The above experiment ultimately resulted in generating control policies that could successfully avoid obstacles and reach their destination in complex environments. For example, the DDQN-trained agent managed to reach its target goal 88% of the time out of a hundred runs in a discrete environment with moving obstacles.
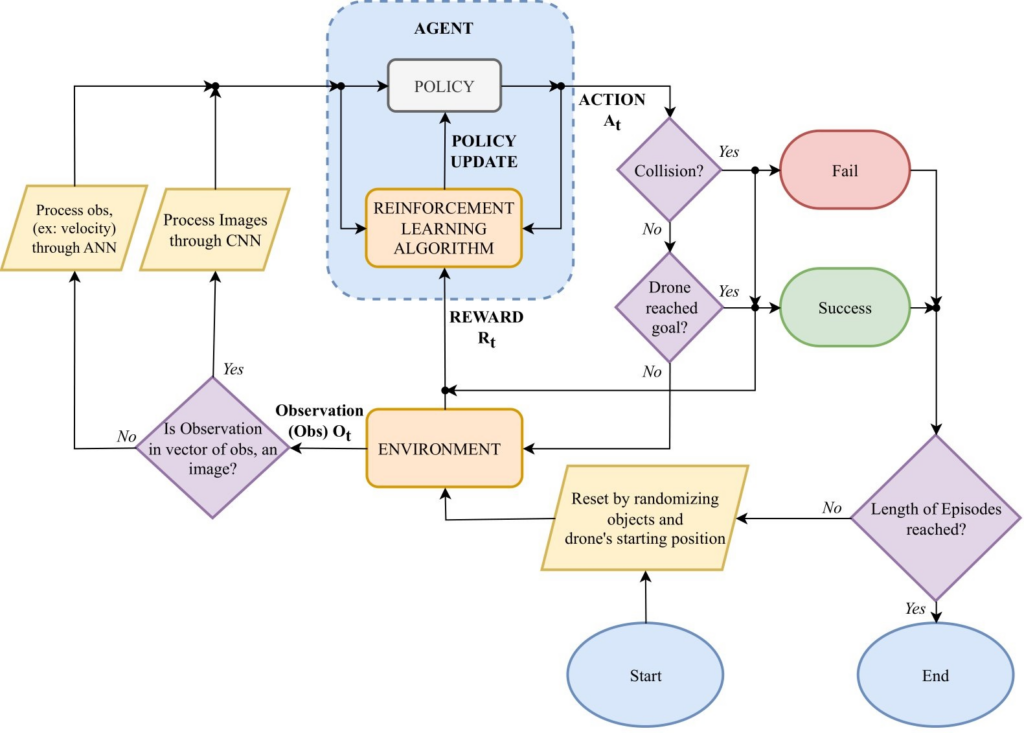
Figure 1. Architectural diagram of the proposed system
Student: Kian Parnis
Supervisor: Dr Josef Bajada