Definition modelling (DM) is a type of language modelling that has been recently introduced in natural language processing (NLP). Aiming to predict and generate dictionary definitions of a target word, the bulk of work carried out in this area concerns high-resource languages, such as English and Chinese, for which large corpora are easily accessible. With this volume of data, context-aware approaches have been used to deal with polysemy and word ambiguity. Such approaches would require contextual information available in the context of the target word. This entails a larger amount of data, which is not always available in the case of less widespread or low-resource languages.
These DM approaches are set back by their dependence on seeing context within the use of the target word to predict these sense-specific definitions. Hence, such models are not applicable in cases where examples of word usage are not available, as is the case with low-resource languages.
DM for low-resource languages has been briefly explored with context-agnostic approaches, wherein the model would generate a definition for a target word without the use of any specific context of usage of this word. This approach is more adaptable to a low-resource setting, such as the Maltese language. Therefore, this study explored context-agnostic approaches in relation to Maltese data, more specifically, models proposed by Noraset et al. [1] and Bear & Cook [2].
Noraset et al. used a neural-network-based approach to learn the word embeddings through incorporating textual definitions. They proposed a DM framework consisting of a definition encoder and word-embedding generator. The definition encoder is a recurrent neural network (RNN) that encodes the textual definition of a word into fixed-length vector representations, whilst the word-embedding generator takes the encoded definition vector and generates the corresponding word embeddings. Bear & Cook presented a sequence-to-sequence translation model that would make use of an attention decoder architecture to thoroughly consider the encoder outputs. They dealt with a low-resource language, Wolastoqey, and hypothesised that the use of sub-word representations based on byte-pair encoding could be applied to overcome challenges with regard to the unavailability of large corpora for training and to represent morphologically complex words.
This study also explored the work of Washio et al. [3] in expanding the model of Noraset et al. to exploit the implicit lexical semantic relations between words to learn more informative and consistent word embeddings. This was done through the addition of a lexical semantic encoder (LSE) component, which learns to encode both the defined and defining words into fixed-length vector representations.
Apart from being used as an evaluation tool for word embeddings, DM could be applied in lexicography to keep dictionaries updated with slang/colloquial or new/emerging words that would not have yet been entered in dictionaries. In the long run, DM could also be beneficial as a reading aid, by providing the user with a definition of an unknown word in an article or blog, by taking into account the word’s context in the sentence.
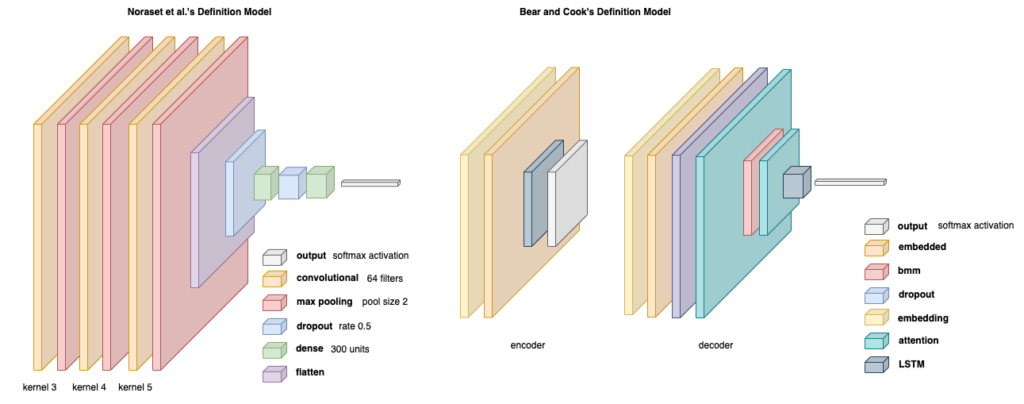
Figure 1. Base models that were explored in this study
Student: Melanie Galea
Supervisor: Dr Claudia Borg