This project presents an application for creating and altering 3D scenes using text input, with the addition of semantic networks. This application would allow users to create scenes by selecting actions and objects from dropdown menus, and entering coordinates, rotation and spacing through input fields. Additionally, the semantic network (SN) function would provide a visual representation of the scene.
The project could be split into two aspects: the scene-creation system and the SN visualisation system. The scene-creation system involved developing a system that would be capable of: placing objects of different shapes and sizes accurately with the correct coordinates and rotations; detecting collisions between objects; creating relationships between objects, such as ‘table with chairs to the left and right’; saving and loading scenes; and featuring complex functions, such as moving or rotating a group of objects. The SN visualisation system involved developing a system that could depict scenes in simple parent-child relationships, with attributes, such as coordinates, rotation and name, being clearly displayed. The system was intended to be relatively simple to use and understand, for the benefit of users who may not have experience with 3D modelling software.
The system was duly tested, and results confirmed the feasibility of SNs for scene creation. The system proved to be an adequate option for dissecting and understanding complex scenes and relationships in a user-friendly manner. Furthermore, SNs proved to be a quick and effective way to find mistakes. The users could also resolutely create and manipulate the objects in the scene using the controls.
The key outcome of this project was the confirmation that SNs are indeed a useful tool for 3D scene creation. Moreover, SNs in the context of scene creation could facilitate the understanding of complex scenes by non-experts.
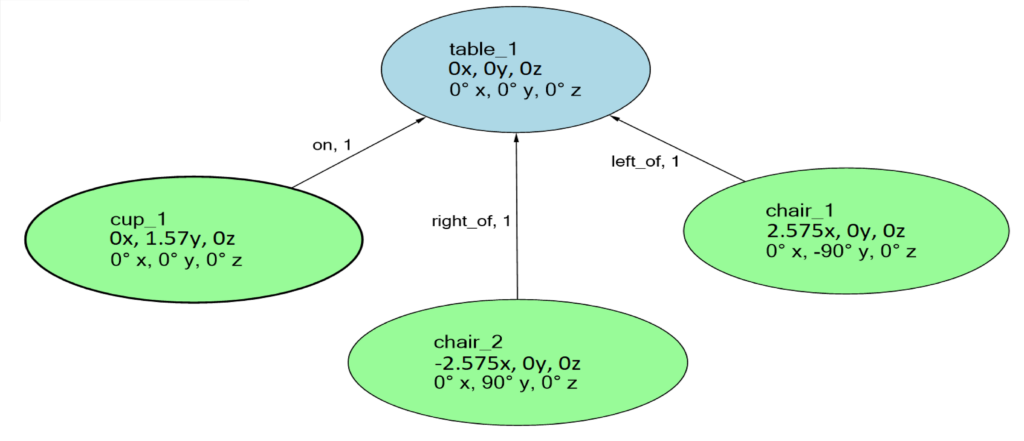
Figure 1. A semantic network representing a scene consisting of a ‘parent’ object (table_1) and 3 ‘children’ objects’ (‘cup_1’ on ‘table_1’, ‘chair_2’ on the right of ‘table_1’, ‘chair_1’ on the left of ‘table_1’)

Figure 2. A 3D visualisation of the scene represented in the semantic network
Student: Gerard Coleiro
Supervisor: Dr Colin Layfield