Ethereum has hosted over 44 million projects since its inception. While past research has been conducted on detecting anonymity and illicit activity over these projects, little to no research has been done on identifying reputability over the projects. Analysing such reputability would be crucial to investors seeking the assurance of identified reputable projects. Hence, this project attempted to analyse projects on the Ethereum blockchain in order to classify these projects as either potentially reputable or not.
The projects could be classified into two main categories: likely-reputable or illicit. This study built upon Farrugia et al’s work [1] which classifies accounts on the Ethereum blockchain, either as illicit or normal.
This research has adopted machine learning (ML), which is the ability of a machine to imitate intelligent human behaviour by using algorithms and statistical models to analyse and draw inferences from patterns in data. Hence, it was deemed essential to collect a list of already known reputable Ethereum projects in order to train the ML model on it. A total of 3,977 likely-reputable accounts on the Ethereum ecosystem were compiled from a reputable source, namely CoinGecko. This source offers a list of leading cryptocurrencies and projects, whilst ranking them according to their market capitalisation.
Once a list of known reputable projects had been compiled, a list of illicit and normal accounts on the Ethereum blockchain was also required in order to train the ML model. This list was collected from Steven Farrugia’s work on classification of illicit activity on the Ethereum blockchain [1].
This identification of reputability could be conducted at two different levels, namely: by analysing at an account level or analysing on a transactional level. For the purpose of this research, a transactional-level analysis was chosen whereby transactions conducted by 8,658 accounts were investigated.
In order to achieve the desired outcome, the proposed solution consisted of the following 4 key steps: i) acquisition of accounts pertaining to be likely-reputable and accounts listed as illicit or normal from Steven Farrugia’s dataset; ii) extracting the required information or ‘features’; iii) classifying accounts using ML techniques; iv) utilising visualisations to display the results in an easy-to-understand manner. This process is outlined in Figure 1.
The top three features with the largest impact on the final model output were found to be: i) ‘average minutes between transactions received’; ii) ‘number of received transactions’, and iii) ‘number of unique addresses from which a transaction was received’. On the basis of the results obtained, it could be concluded that the proposed approach is highly effective in classifying accounts as likely-reputable or not.
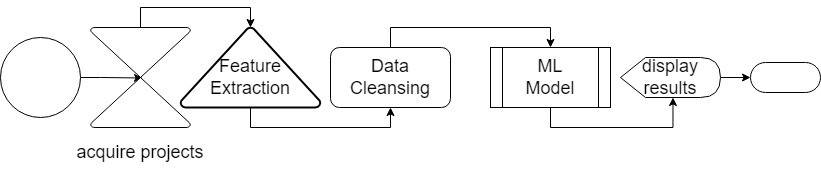
Figure 1. Architectural overview of the proposed solution
Student: Cyrus Malik
Supervisor: Prof. Joshua Ellul