One of the most challenging aspects of creating and designing games is in making them as enjoyable as possible for the players. Given the difficulty and time taken for this task, an application that could learn which parts of the game players might prefer over others would be particularly useful. This type of application would be invaluable in determining the parts of the game a player likes the most and those that could be removed or improved upon.
The goal of this final-year project was to create a preference learning (PL) model that could determine which instances of gameplay would be preferred by the user. The data used for this project was obtained from the AGAIN dataset, a collection of gameplay videos that have been annotated by the players to reflect their excitement levels throughout the gameplay. This data was then passed through a number of neural networks, which are evolved to find the one that produces the best model.
The annotation was done by the players while rewatching a video of their gameplay and marking their level of excitement at every moment of the gameplay. Separate files contained the relevant game data on these videos, including the excitement values of the user at particular increments of time. The images were extracted on the basis of these increments and then paired up with their respective excitement values.
The base model used was RankNet, a PL model that could select two objects and determine which one would be preferred based on the training data provided. This model takes the two objects as input and processes them through the network to learn their features. It then outputs a single value that reflects which object it considered to be the preferred one. The version used for this project worked in the same way, with two randomly chosen images being chosen and compared to learn the preferences for each game.
The neural networks generated to create the PL model were made using the Neural Network Intelligence toolkit. This toolkit allows users to implement a number of techniques that could be used to help improve neural networks. For this project, the neural architecture search (NAS) component was used to evolve the architecture of the neural network itself. This involved defining a number of possible mutations that could occur within the architecture, which would be chosen by a search strategy. The models were tested within an experiment that trained and tested a defined number of model configurations.
The results of each experiment were displayed through a number of graphs outlining the various aspects of the model throughout the training process. These include: displaying the accuracy of the model through time; the mutations that worked best within each model; and other metrics that outlined the performance of each model. These results indicate that the generated models can determine user preferences accurately, with varying degrees of success within the different configurations tested.
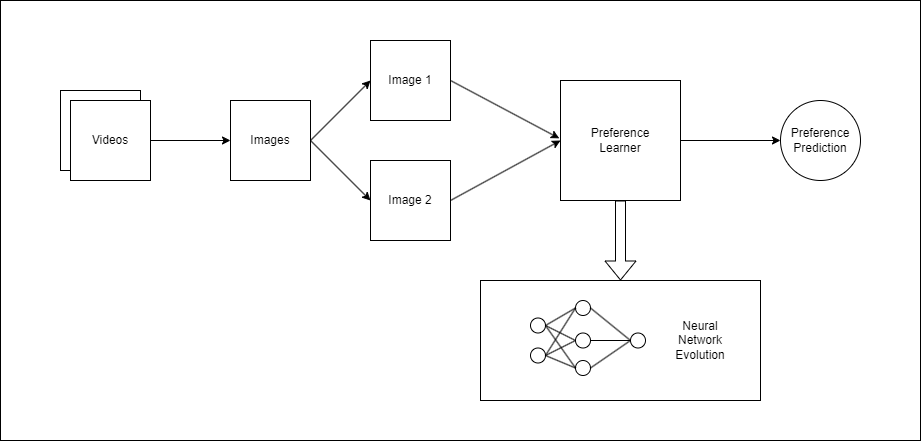
Figure 1. Outline of the training process
Student: Matteo Sciberras
Supervisor : Dr Vanessa Camilleri