Sports betting could be defined as the activity of attempting to predict the outcome of a sports event and placing a wager on the said outcome. With advancements in internet and e-commerce technology, a relatively new type of betting ‒ online sports betting ‒ has grown in popularity.
Bookmakers create their odds using machine learning (ML) and mathematical models that rely on a plethora of data to use the odds that could maximise their profits. Although bookmakers have extremely accurate models for predicting sports-event outcomes, creating a model that would outperform theirs is theoretically possible. Therefore, if a model could outperform a bookmaker’s model, then it would be able to predict sports-events outcomes at a higher accuracy. This would mean that, if punters were to place bets based on this model consistently over an extended period of time, they could make a profit.
This final-year project proposes a model that could rival that of the bookmakers. The main focus was on a specific type of bet in the National Basketball Association (NBA) known as player props. In essence, this involves placing a bet on a specific player’s performance, as opposed to a team winning or losing a game.
To achieve the set objective, it was necessary to identify a dataset that would be large enough to train an ML model. Unfortunately, there were no publicly available datasets, which brought about the need to create a new dataset using web scraping. The task also required a dataset that would include player performances. The NBA stats application programming interface (API) for player statistics was, on the other hand, publicly available, thus allowing the gathering of the data required for training. Subsequently, it was decided to use three models that could use sequential data, since they were to be trained on the previous performances of a player. The selected models were: recurrent neural network (RNN), long short-term memory network (LSTM), and a transformer.
Once each model was trained and hyperparameters tuned, each model was used with different betting strategies to investigate which approach would give the punter an advantage when placing bets. The final results showed that, overall, the transformer was the most accurate, followed by the LSTM and, lastly, the RNN. However, although the transformer proved to be the best, it was still incapable of outdoing the bookmakers’ models. Therefore, it could not generate the desired profits for the punter.
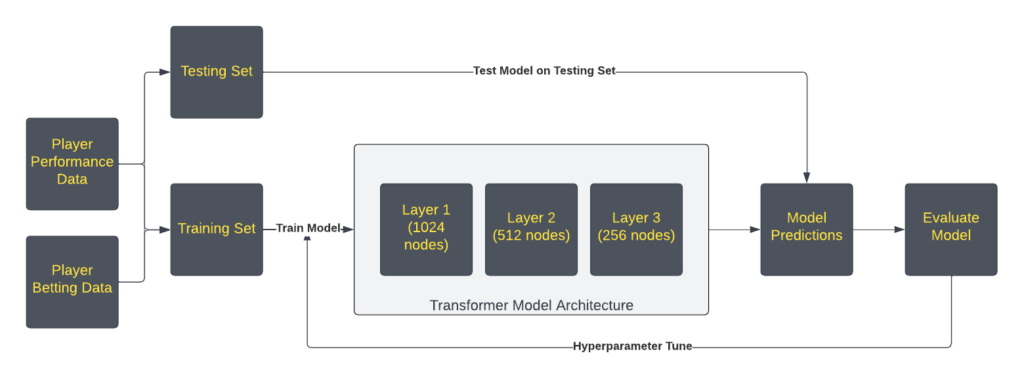
Figure 1. A brief visual representation of the data and model flow that was used in the project
Student: Edward Thomas Sciberras
Supervisor: Dr Kristian Guillaumier