The aim of this work was to develop an intelligent agent capable of playing a two-player score-based board game. This was achieved by determining which reinforcement learning (RL) algorithm would be the most suitable for the board game Jaipur.
This board game consists of two players playing against each other by taking turns to trade cards in order to earn points towards winning the game. Each player would have a set of ‘hand’ cards, which are only visible to the respective player, as well as a set of ‘herd’ cards which are visible to both players. Moreover, during gameplay, there would also be 5 cards in the ‘marketplace’, which are always visible to both players. The remaining cards would be shuffled and flipped over to be dealt to the marketplace whenever a player would pick a card.
Jaipur has a number of elements that render it unique and challenging to solve, which is one of the reasons for being selected for this project. Additionally, the game was chosen for this project on the grounds that no publicly available research could be found as to how to solve the challenges posed by this game.
The difficulty with the game is twofold. Firstly, it has a large action space, with a total of 25,469 possible actions that could be performed during gameplay. Moreover, the game contains a partially observable environment since it contains hidden information, such as the opponent’s hand cards and the cards in the deck. Apart from this, the game contains stochastic actions, as performing the same action may lead to a different outcome. Hence, these factors make it harder for the agent to learn which actions would be the best to take.
Furthermore, Jaipur also contains a dynamic environment, which means that the agent must adjust its play style based on the current opponent, due to the fact that different opponents have different styles of play. Lastly, the game contains actions that either provide immediate rewards and good long-term consequences, immediate rewards but bad long-term consequences, delayed higher future reward, or delayed lower future reward. Therefore, it would be up to the agent to analyse the game state and learn when to take the immediate reward and when to wait for a more long-term reward.
The first task towards solving the problem described above was to implement a working version of the game. This was achieved by implementing all the game rules and steps using Python. Subsequently, the game was developed as an RL environment by creating an OpenAI Gym environment with the use of PettingZoo. This is a multi-agent RL framework that allows the training and testing of different algorithms to take place. In order to achieve this, the appropriate observation and action spaces were also developed, to capture the game state information.
The final task consisted in testing and evaluating different RL algorithms, such as DQN and PPO, amongst others, in order to derive the best RL algorithm used based on the agent’s performance.
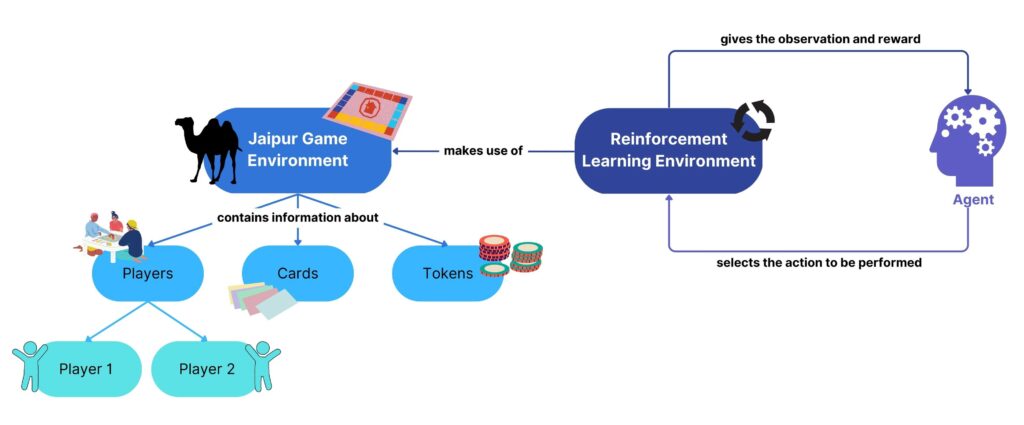
Figure 1. Agent-environment interaction loop
Student: Cristina Cutajar
Supervisor: Dr Josef Bajada