Our voice tends to change depending on our emotional state. Speech emotion recognition (SER) facilitates the detection of the emotion a person might be experiencing from the audio signal of their speech, through the use of machines. In view of its success in image recognition, deep learning (DL) is also leading the way in SER. However, the results obtained to date have not matched those achieved in image recognition. Hence, this project focused running experiments to find possible ways of improving results in SER.
Experiments were run on the RAVDESS dataset, which is a collection of two statements acted out in eight emotions by twenty-four different actors. The model being trained was a pre-trained version of Facebook’s Wav2Vec2, which is an example of state-of-the-art natural language processing. The model was fine-tuned to classify the RAVDESS dataset ‒ which is a process known as transfer learning.
In essence, a DL model is an extension of the artificial neural network, which is loosely based on the activity of neurons in the human brain. One of the techniques used is the tweaking of hyper-parameters, such as the number of neurons in different layers of the network, the learning rate, the duration of the training period, and the mathematical formulae used in its computations. Another technique that was attempted is known as data augmentation, where the audio files would be manipulated in such a way as to make them sound like different individuals, such that the model would be presented with more examples to learn from.
During the validation process, particular care was given to using augmented data exclusively for training, and never used to test the effectiveness of the model. Data augmentation offered small, yet promising, improvements in the results. This could be considered an encouraging outcome, when taking into account that augmenting data tends to be faster and cheaper than collecting it.
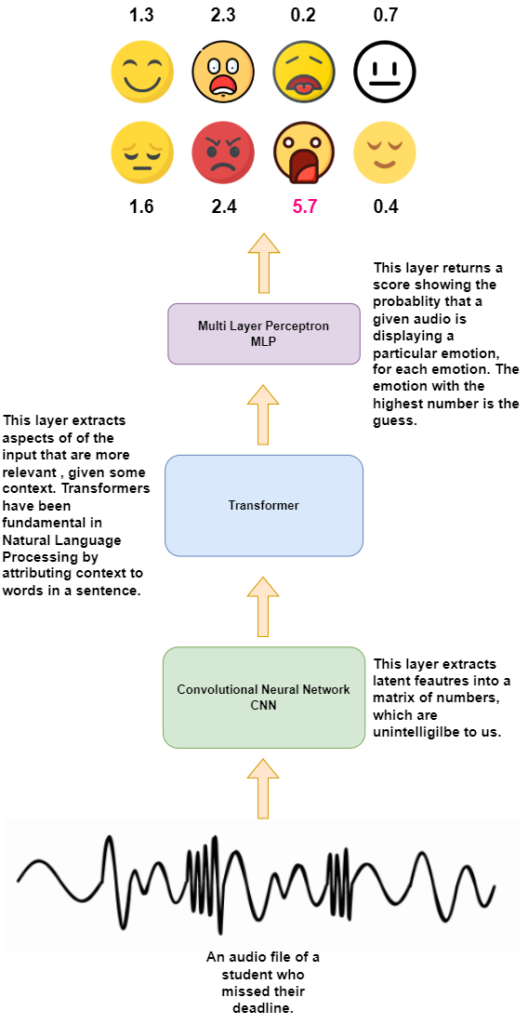
Figure 1. High-level diagram of the model used and how it uses an audio signal to predict
an emotion.
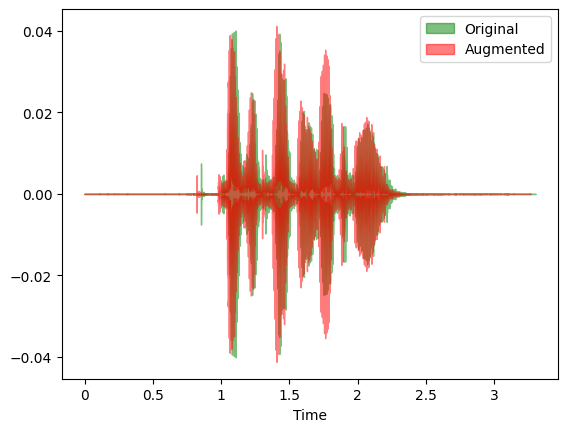
Figure 2. Two superimposed audio waves from the RAVDESS dataset, where the area in green is the original wave in the dataset, and the one in red is the augmented wave;
the darker regions are overlaps
Student: Daniel Farrugia
Supervisor: Prof. John Abela