The way readers consume news has evolved as a result of the rise of the internet and social media. Over the last two decades, newsrooms have expanded their operations online, and their stories are now published on social media, online web portals, and/or mobile applications. The internet has democratised and facilitated journalism, while social media has made it easier to exchange and spread news.
Although this is generally positive, there may be certain instances where it has a detrimental impact. If the news is biased or inaccurate, it may distort the public’s perception of critical issues. The Automated News Aggregator (ANA) attempts to solve this problem by providing an online platform. Here, articles related to the same subject published by multiple newsrooms, are aggregated into one article with minimal bias.
Currently, existing systems just group similar articles and stories together. This project takes it a step further by aggregating the article’s content, producing as little bias as possible all the while working in a transparent and responsible manner.
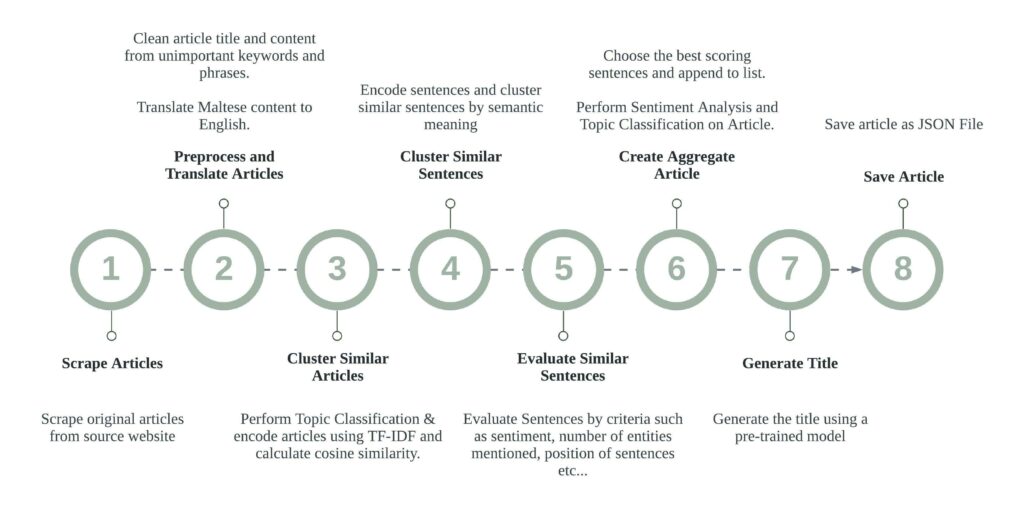
The original articles are scraped from their respective websites, pre-processed and translated. Using TF-IDF, articles are made into a vector, in order to be queried and grouped into similar articles. Each sentence of the similar articles is split and inserted into one list of sentences. The sentences are then embedded into sentence vectors, and clustered by semantic meaning. Clusters of similar sentences are then processed and scored according to specific criteria such as the sentiment of a sentence, the number of entities, the position of a sentence relative to the article, and use of pronouns. The best scoring sentence is then chosen from its cluster, and added to a list of sentences for the newly aggregated article.
ANA takes online news portals on a new trajectory, encouraging consumable and unbiased media.

Student: David Dimech
Course: B.Sc. IT (Hons.) Artificial Intelligence
Supervisor: Prof. Alexiei Dingli