Neural machine translation is the task of translating text between a source language and a target language using artificial neural networks. Typically, training neural machine translation models is computationally expensive and requires vast amounts of data in order to build a model which is able to translate accurately enough for use in the real-world. Some of the best translation models in the world such as those developed by Google and Facebook are trained on billions of sentences where data is available. They provide coverage for over 100 languages, however many of these languages do not have large parallel corpora and this becomes evident from the translation output.
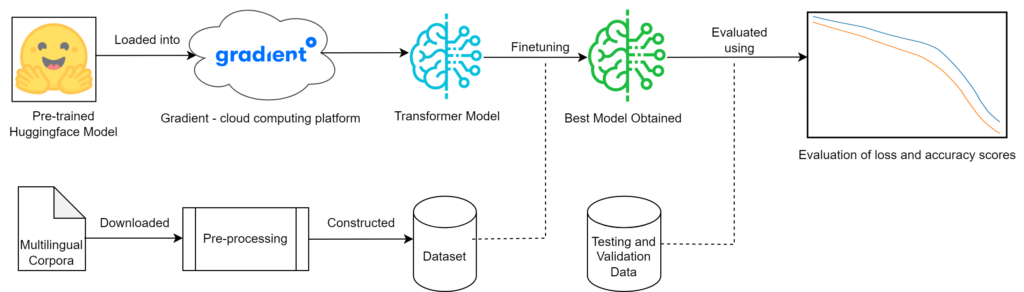
This project focuses on neural machine translation in the context of low-resource languages, which possess far less online corpora available when compared with other widely spoken languages such as English, Spanish and Mandarin. A dataset was constructed from an amalgamation of different multilingual sources in order to create a single larger multilingual corpus which included the English, Danish, German, Icelandic, Norwegian and Swedish languages. This sequence involved pre-processing texts, removing sentences longer than a certain length and splitting sentences into smaller units called ‘tokens’.
Existing models which were already pre-trained for neural machine translation were obtained from the Hugging Face repository. These models were further trained and fine-tuned using the new dataset. These models are known as Transformers and have become the backbone of the architectures used by some of the best translation models. In order to attain the best performance and results, a cloud computing platform Paperspace Gradient was used, where all models were fine-tuned and trained on high-performance hardware on the platform. The accuracy of these models was evaluated using additional datasets provided by the organisers of a shared task in the Sixth Conference on Machine Translation. The accuracy of the system itself is compared with that of other models submitted to the shared task, using evaluation metrics including BLEU, TER and chrF. In conjunction, other pre-trained models were obtained and acted as baselines. These were not fine-tuned with any other data and used “out of the box” to give a clearer indication of the impact fine-tuning had on the translation tasks.
Experiments were conducted to examine the relationship between the accuracy of the model and training with low-resource languages. Different instances of the pretrained models were fine-tuned using smaller subsets of the larger constructed dataset. First, this involved starting from just 10% of the complete dataset and examining accuracy, then repeating this experiment with a larger amount of data used; this repeated until the entire dataset was used. This was done to investigate the question “How little data can be used and still have the system be accurate?” From the experiments performed, it was found that the additional training and fine-tuning performed on each model provided a more substantial benefit in accuracy when larger sets of the constructed dataset were used. The relatedness of the North-Germanic languages used in this task was also provided an overall increase in translation quality.
Student: Jake Sant
Course: B.Sc. IT (Hons.) Artificial Intelligence
Supervisor: Dr Claudia Borg