Businesses and organisations across the globe are continuously implementing solutions that utilise ASR (Automatic Speech Recognition) and NLP (Natural Language Processing) to streamline their operations. One such task is that of automatic transcription of dialogue followed by conversation summarisation, which proves to be highly valuable in the use case of lengthy meetings with multiple speakers.
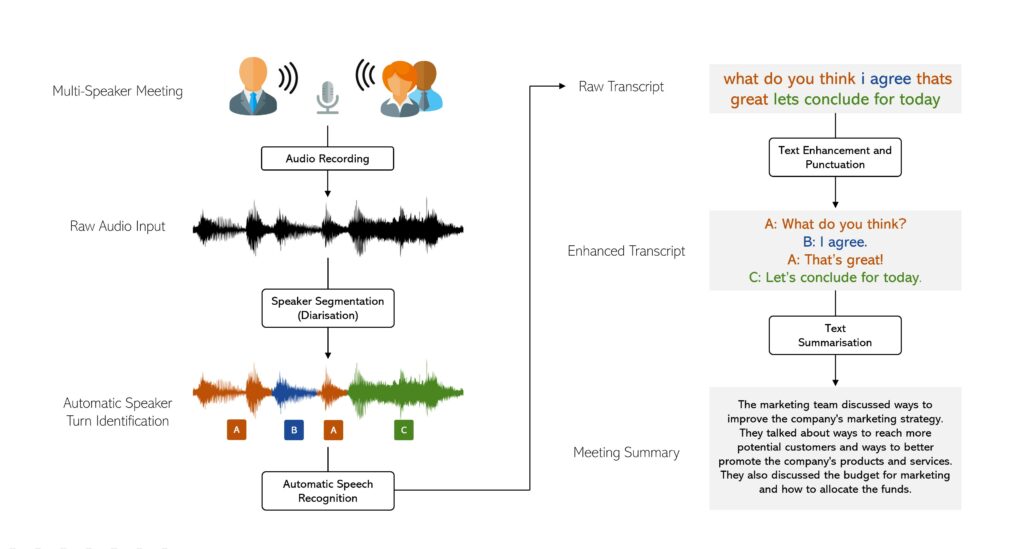
The work aimed to apply automatic speech recognition to audio obtained during meetings, simultaneously segmenting between two or more speakers within these conversations. This proved to be a challenging task due to non-ideal acoustic conditions coupled with regular speech overlaps (participants speaking over one another). Subsequently, the work focused on producing a brief summary containing the main ideas of the conversation. This task was also non-trivial due to the non-conventional structure of conversational text, with the main points being scattered across several speakers and utterances.
Following an in-depth analysis of numerous relevant state-of-the-art models and techniques, a system was implemented that achieved this goal, successfully transcribing and summarising meeting recordings from a collection of business meetings. This system comprised of a pipeline of models for each respective sub-task, the first of which is Speaker Diarisation which detects speaker turns, answering the question “who spoke when?” This is followed by ASR, also known as speech-to-text, obtaining the spoken words for each speaker. This text is punctuated using a sequence-to-sequence model and the result is a complete and enhanced transcript of the meeting. Finally, this transcript is used as the input of a summarisation model that returns a summary highlighting the salient points of the conversation.
Two deep learning models were trained for the summarisation task on data obtained from a meeting corpus, appended by synthetic data from the robust GPT-3 model. This process was carried out in order to achieve the results of a high-resource model with significantly less data. In the process, this increased the robustness of the summarisation model towards noise and errors in the transcript obtained.
Subsequently, the system was evaluated as a whole by altering various parts of the pipeline and examining these changes on the overall output of the system. These experiments were conducted in order to gain insight into which components the system is most dependent on and which can be sacrificed in order to save computational resources. This paves the way for such a system to be implemented in low-resource languages and focuses efforts on areas which are most crucial for advancement in this area.
Student: Mikea Dimech
Course: B.Sc. IT (Hons.) Artificial Intelligence
Supervisor: Dr Andrea DeMarco
Co-supervisor: Dr Claudia Borg