Definitions are the main means through which humans communicate and learn the meanings of concepts. The purpose of a dictionary is to help in the generalisation and circulation of these meanings. However, keeping a dictionary up-to-date is tedious work, with several new definitions being introduced as language evolves and new words enter the language or existing words shift in meaning. Thus, automated extraction of textual definitions is beneficial. It can assist the curation of dictionaries and can also be used in a language learning environment whereby learners have access to definitions of new terms encountered.
The automatic extraction of definitions from text using machine learning techniques is a growing research field. Typically, this was always done in a limited, structured, well-defined way using pattern matching. Recently, more advanced techniques, namely neural networks, are being used to solve this problem. These also allow the ability to recognise definitions without specific defining phrases, such as ’is’, ’means’, ’is defined’.
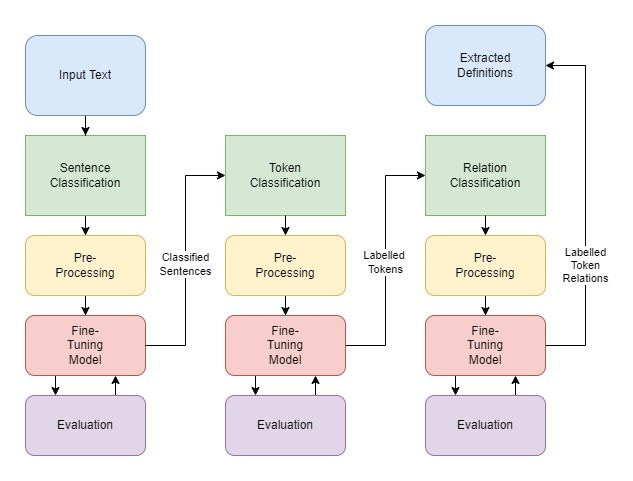
In this Final Year Project, there are three main components which make up the Definition Extraction pipeline. The first component simply classifies whether a given sentence is a defining sentence or not. The second component classifies each token in the sentence with a label that indicates its type, including ‘term’, ‘definition’, ‘alias’ or ‘referential term’ of a sentence. This label feeds into the following component. The third and final component labels the relation between each tag in a sentence, which can be, ‘direct-definition’, ‘AKA’, ‘supplements’, amongst others, finally forming a definition.
For each of the three steps mentioned above, a pre-trained neural network is fine-tuned for its specific purpose. Naturally, in order to train a neural network, a large amount of data is needed. For this project, the DEFT Corpus was used, which was constructed specifically for definition extraction and is the largest annotated semi-structured corpus for this field, containing sentences from open-source textbooks covering a wide range of subjects as well as the US Securities and Exchange Commission EDGAR (SEC) database.
The main aim of the project is to experiment with and analyse various preprocessing techniques and pretrained language models (including BERT, RoBERTa and ALBERT) to solve each of the three components. These large neural language models have been used in many NLP applications. Our research question focuses on comparing the impact of these different models on the definition extraction pipeline and the individual component. The experiments with these language models will include freezing the weights and fine-tuning them, as well as checking the effect of balancing classes in the training data.
The results achieved are then compared to those of the DEFT-Eval competition, which is a definition extraction competition that uses the DEFT dataset. This serves as a good benchmark. However, our primary focus remains a comparative study of the impact that the large neural language models have on the definition extraction task.
Definition extraction can be beneficial in a variety of situations, such as building dictionaries or knowledge graphs, which benefit from increased connectivity and relevance, especially for question-answering machines.
Student: Paolo Bezzina
Course: B.Sc. IT (Hons.) Artificial Intelligence
Supervisor: Dr Claudia Borg