This work will take a supervised machine learning approach to address the problem of ingredient detection – which involves recognizing a number of ingredients within an image. Various neural network designs will be manoeuvred to yield an acceptable performance for this Computer Vision-related task. The niche for recognizing ingredients has grown massively in recent years, with food-logging increasing in popularity as a means to monitor one’s personal diet. In times where dietary awareness is skyrocketing, ingredient recognition automatically demands further experimentation en route to perfecting existing solutions. For example, such a technique may be extremely useful to detect vegetarian/vegan-friendly food, as well as for lactose intolerance testing.
The exact position of the ingredients is not of any interest to this experiment, as that lies entirely under a different bracket of computer vision – Localization. The objective is to simply mark the presence of an ingredient in the input data (hence detection). However, this task is not quite straight-forward, as this can be considered a multi-label classification problem. This implies that dishes can contain zero, one or multiple ingredients, hence an image can be classified into a number of different classes.
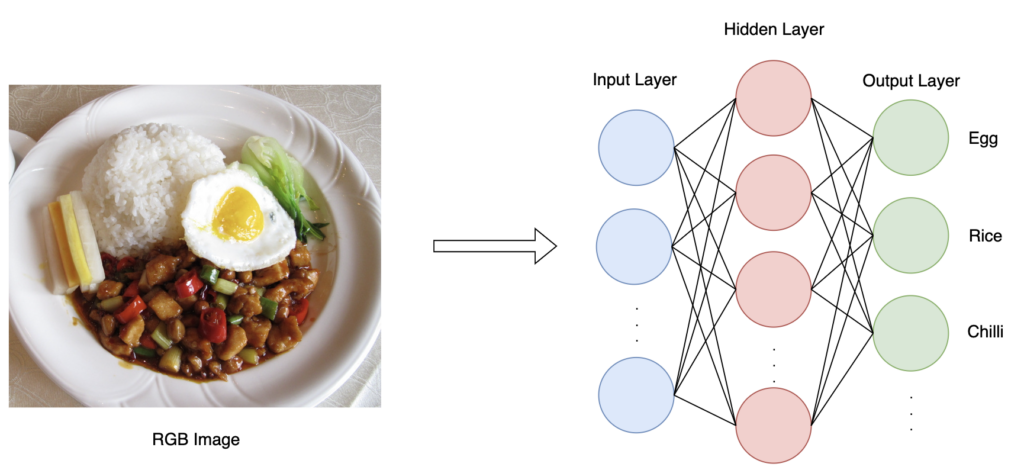
Deep Learning is a concept in which architectures are inspired by the human visual cortex, composed of interconnected neurons. These neurons are grouped into layers, where they communicate adjacently to transport information from the input to the output layer. A Convolutional Neural Network (CNN) is fit to handle such problems, as it uses a mathematical function called convolution to extract features from two-dimensional data. Depth plays an important role, as it is usually indicative of the complexity and capability of the network. However, depth and other factors may have to be sacrificed due to hardware and timing limitations.
One disadvantage of CNNs is that they require large amounts of data to undergo successful training. Even more so for ingredient detection, food has high visual variance, hence robust recognition requires capturing different outcomes of cooking and preparation. Using a dataset containing 169,000 food images of Chinese cuisine, this project will consist of designing and training a model, capable of recognizing a number of ingredients present in a dish. Note that,
although there are 408 ingredients present in this dataset, this work might consider only a subset of these ingredients, depending on the model’s performance.
This project aims to analyse networks which resemble both Alexnet and Resnet, with the hopes of achieving satisfactory results. These models consist of different techniques which allow learning to take place in a feasible manner, i.e. with an acceptable number of parameters, while avoiding overfitting.
Performance is analysed through the use of certain evaluation metrics, suited for multi-labelled solutions. Such metrics should take into account the non-linearity of the data, as well as the multi-labelled outputs. There are not yet an official results, however it is suspected that Alexnet reaches an F1 score of around 35%.Through Resnet’s residual blocks implementation, a significant improvement over this value is expected.
Student: Luke Dalli
Course: B.Sc. (Hons.) Computing Science
Supervisor: Prof. Reuben Farrugia