The aim of this dissertation is to analyse words with in the Voynich Manuscript, an elusive manuscript that no one understands, to determine if it might have any meaning hidden within. This was done by applying Natural Language Processing techniques to remove stop words, which are words that mainly serve a sole grammatical purpose, and to plot co-occurrence graphs. Furthermore, these techniques were also applied to existing texts in old English and old Italian for there to compare any patterns found. Furthermore, all the documents will be randomly scrambled to see if any patterns found hold in random text.
The documents were pre-processed to make them workable by removing stop words, punctuation, and digits. Following this, co-occurrence graphs were generated for each document containing
words, word pairs and their frequencies. Using this data, an algorithm was created to calculate the skewed pairs of each document appearing above a certain frequency threshold. For example, if we
have word pair P and its inverse pair Q, a skewed pair would be one where P occurs much more frequently than Q if it even appears at all. This skewed pair calculation was done for all documents and their randomised counterparts.
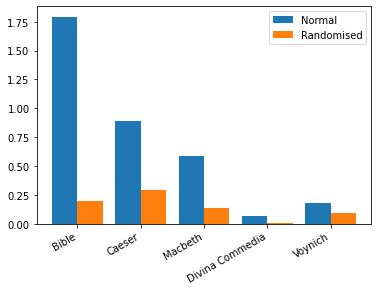
The results were then plotted together in a graph showing the ratio of skewed pairs to regular pairs taken to a percent. These results showed that there was a massive difference between the English and Italian documents and their random counterparts, where the normal version scored much higher. However, the results for the Voynich were a little more even with the randomised version only scoring roughly half as much as the normal variant. This may suggest that the
manuscript is not randomly generated text, however it could point to the Voynich being some sort of code or cipher.
Commedia (Inferno)
Student: Andrew Caruana
Course: B.Sc. IT (Hons.) Software Development
Supervisor: Dr Colin Layfield