The popularity of online news portals over recent years has resulted in these repositories of articles being augmented with readers’ comments in response to the respective articles [6]. The main objective behind this project is to investigate the relation between articles and commentators, and to analyse and visually represent how different users comment across articles. This information includes data, such as the manner in which each user reacted to different articles, and which topics they preferred commenting about. An overview of the main components, which will be discussed in further detail, has been provided in the design flowchart accompanying this abstract.
The first task was to obtain access to news articles of a popular local news portal and store these in a MongoDB database. The extracted data covered a period of 15 months, ranging from January 2019 to March 2020, and contained 14,188 articles and 228,249 comments from 5385 unique users.
One of the main challenges encountered was to detect the topic/s associated with the articles. The initial attempts revolved around supervised learning techniques that required using a labelled corpus of articles divided into 5 sections: business, entertainment, politics, sports and technology. Different machine learning models such as naïve Bayes and support-vector machines were used as an attempt to make the supervised approach as effective as possible. However, the lack of an available local dataset meant that it was necessary to resort to a foreign one, instead. This approach produced poor results, as the significant difference in named entities caused certain documents to be misclassified. Hence, a different approach was chosen, namely the unsupervised topic- modelling technique called latent Dirichlet allocation (LDA). This was preferred due to its ability to detect and show latent topics using the term frequencies of the different articles, thus generating topics closely related to the dataset. It is also worth mentioning that a number of studies recorded the success of the LDA technique in modelling news topics [1, 3, 4].
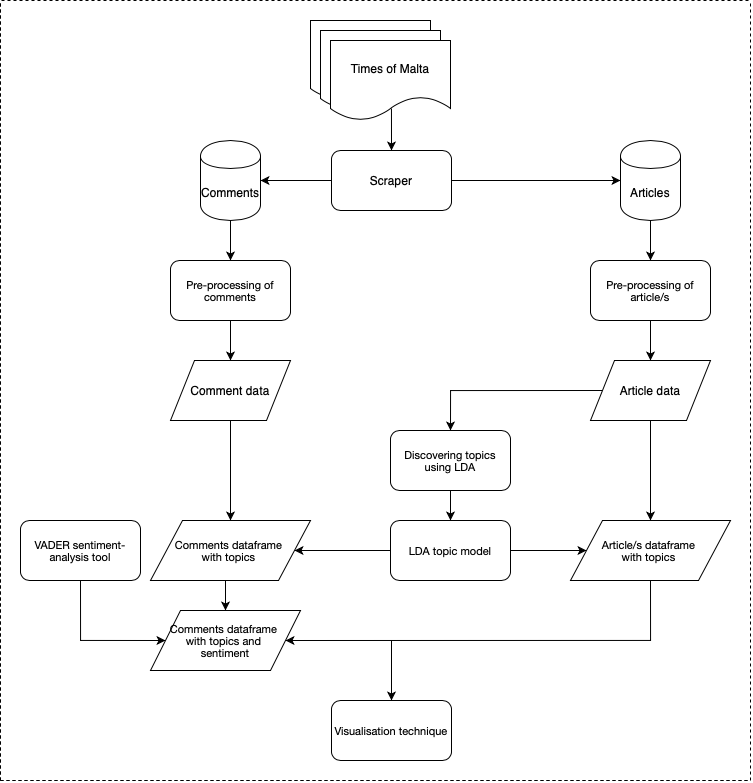
Once the news articles were classified, the next step was to profile the authors of the comments. The two main challenges underlying this task included detecting topic relevance and analysing sentiment to understand how users reacted to the article. With regard to the former, surface-based techniques based on cosine-similarity and Jaccard-similarity were adopted initially. However, results were not sufficiently productive due to the varying length of different articles and comments. Consequently, a different approach was identified, which was based on the LDA model created from the articles. This approach was applied to the comments, since it could recognise the most frequently used terms in order to categorise the topic accordingly [7]. To address the ‘sentiment’ aspect it was deemed best to utilise the gold-standard, lexicon-based approach of the sentiment- analysis tool Vader (Valence Aware Dictionary for Sentiment Reasoning) [2, 5]. This tool is specifically attuned to analyse comments posted on social media. It also proved successful in other domain contexts, including New York Times editorials, and hence deemed suitable for the purposes of this study.
To allow users to visualise the analysis of the article- comments relationship, a dashboard-style interface was developed, through which a researcher could select specific individuals who have submitted a comment, and receive analytical data about them. This data would include the user’s overall sentiment, how topical the user’s comments were and their favourite topic(s).
References/Bibliography:
[1] Anton Barua, Stephen W Thomas, and Ahmed E Hassan. What are developers talking about? an analysis of topics and trends in stack overflow. Empirical Software Engineering, 19(3):619–654, 2014.
[2] Clayton J Hutto and Eric Gilbert. Vader: A parsimonious rule-based model for sentiment analysis of social media text. In Eighth international AAAI conference on weblogs and social media, 2014.
[3] Carina Jacobi, Wouter Van Atteveldt, and Kasper Welbers. Quantitative analysis of large amounts of journalistic texts using topic modelling. Digital Journalism, 4(1):89–106, 2016.
[4] David Mimno, Hanna M Wallach, Edmund Talley, Miriam Leenders, and Andrew McCallum. Optimizing semantic coherence in topic models. In Proceedings of the conference on empirical methods in natural language processing, pages 262–272. Association for Computational Linguistics, 2011.
[5] Alejandro Moreo, M Romero, JL Castro, and Jose Manuel Zurita. Lexicon-based comments-oriented news sentiment analyzer system.Expert Systems with Applications, 39(10):9166–9180, 2012.
[6] Manos Tsagkias, Wouter Weerkamp, and Maarten De Rijke. Predicting the volume of comments on online news stories. In Proceedings of the 18th ACM conference on Information and knowledge management, pages 1765–1768, 2009.
[7] Jing Wang, Clement T Yu, Philip S Yu, Bing Liu, and Weiyi Meng. Diversionary comments under political blog posts. In Proceedings of the 21st ACM international conference on Information and knowledge management, pages 1789–1793. ACM, 2012.
Student: Mikhael Cutajar
Course: B.Sc. IT (Hons.) Artificial Intelligence
Supervisor: Dr. Charlie Abela