Card-based payments are increasingly becoming the standard payment method by consumers. Indeed, between 2017 and 2018 global expenditure attributed to card payments grew by 17.7% to $40.582 trillion.
Many industries rely heavily on card-based payments as an efficient means of collecting money from consumers, as is the case with e-commerce. As the number of annual transactions made through the various types of payment cards increases, losses due to fraud are also on the rise and these are expected to amount to $35.67 billion globally by 2023 [1]. Given the quantity of transactions being processed on a daily basis by financial institutions, and the substantial losses being incurred due to fraud, the said institutions must implement fraud-detection systems that are cost-effective, automated, and offering high accuracy with minimal human intervention. This issue has not gone unnoticed by researchers and strides have been made in early-fraud-detection systems, which make use of machine learning techniques. However, the imbalanced distribution between fraudulent (minority) and non-fraudulent (majority) is challenging for many traditional learning algorithms, which are ill-suited to handle such large-class imbalances [2]. So much so, that models trained on these datasets tend to be biased
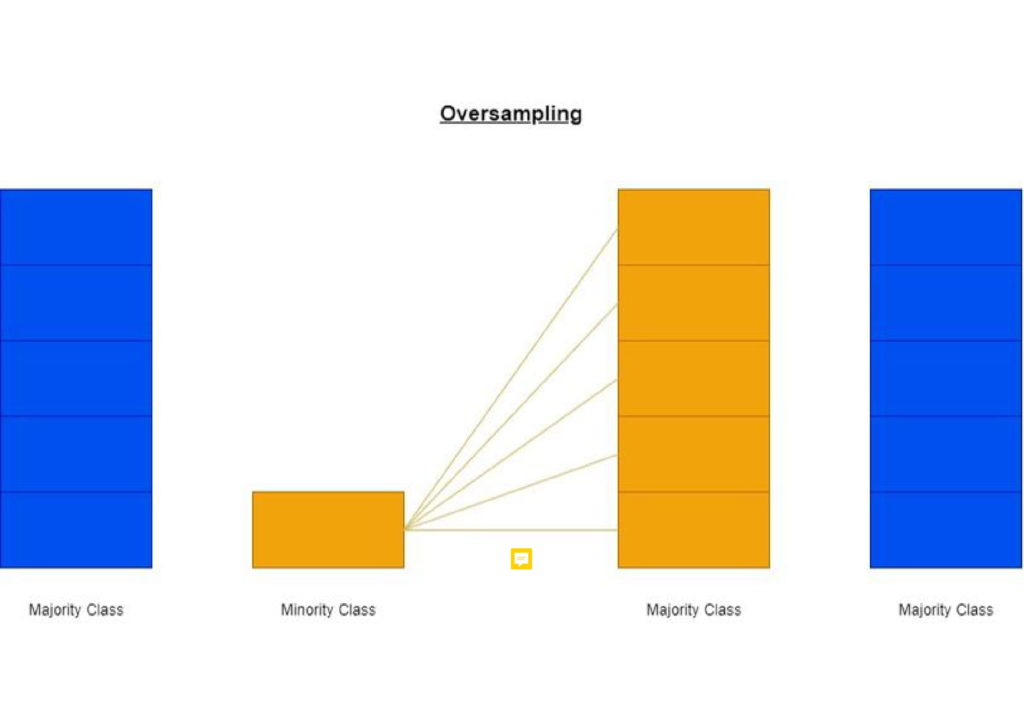
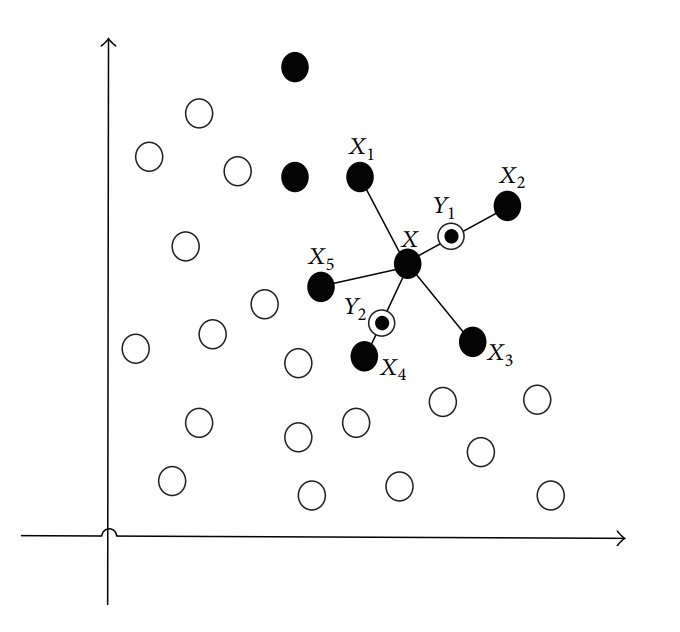
towards the majority class and yet still achieve high accuracy scores because the minority class is ultimately a very small percentage of the dataset.
In this final year project, a data-level approach has been used to overcome class imbalance by incorporating oversampling techniques that make use of synthetic data. Within this domain, a technique known as Synthetic Minority Over-Sampling Technique (SMOTE) [3] has been used extensively, yet the development of SMOTE has spawned may variants of this technique, which have not been examined as extensively. This project evaluates other popular variants of the original technique, in conjunction with machine learning techniques that have been considered in relevant literature to perform well in this domain. These techniques are: XGBoost, random forest and Gaussian Naïve Bayes. Finally, the project sought to highlight the most effective algorithm for card fraud detection purposes.
References/Bibliography:
[1] “Card Fraud Losses Reach $27.85 Billion,” Nilson Report – Card Fraud Losses Reach $27.85 Billion. [Online]. Available: https:// nilsonreport.com/mention/407/1link/. [Accessed: 03-Aug-2020].
[2] G. M. Weiss and F. Provost, “Learning When Training Data are Costly: The Effect of Class Distribution on Tree Induction,” Journal of Artificial Intelligence Research, vol. 19, pp. 315–354, 2003.
[3] N. V. Chawla et al, “SMOTE: synthetic minority over-sampling technique,” Journal of Artificial Intelligence Research, vol. 16, pp. 321-357, 2002.
[4] X. Yonghua, L. Yurong, and F. Qingqiu, “Research Article Imbalanced Data Sets Classification Based on SVM,” hindawi.com. [Online]. Available: https://www.hindawi.com/journals/ddns/2015/562724/. [Accessed: 05-Aug-2020].
Student: Julian Demicoli
Course: B.Sc. IT (Hons.) Computing and Business
Supervisor: Dr. John Abela