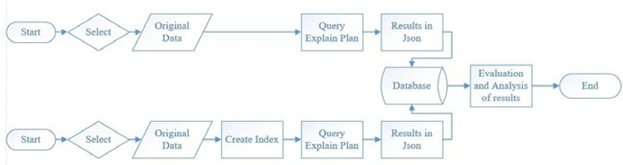
Figure 1. Logical-design diagram of the methodology used in the study
Novel applications rely on data with a high number of attributes and a much richer set of data types (e.g. spatial data). Furthermore, applications that gather data from sensors generate datasets that include numerous dimensions. It is, therefore, recommended that indexes to be utilised in database management systems (DBMS), in order to retrieve data more efficiently against the cost of maintaining them [1].
Many researchers have endeavoured to create indexing solutions for managing high-dimensional data. A staggering number of factors affect successful indexing on multi- dimensional data. Moreover, single-dimension indexing structure techniques do not generally apply in multi- dimensional databases.
When indexing spatial data, the R-tree indexing structure is normally used. However, when using indexes on PostGIS tables, PostGIS recommends the use of the GiST index framework. Furthermore, spatial indexing is provided with an R-tree over GiST scheme, as this framework allows data entries that are larger than 8Kb in size. This project plans to test whether a multi-dimensional index artefact would be worth introducing. Two types of datasets were used: a spatial dataset and a high-dimensional dataset. Different queries were run on the different datasets, and subsequently the query plan was recorded and analysed. The query planner was configured to run the queries under
three different scenarios. The first scenario being with no indexes, a second scenario where the index was forcibly used, and finally giving a free rein to the enabled optimiser, i.e. where the query planner would be free to choose the execution plan.
This evaluation focuses on the differences of the recorded query plans, and calculations were made to determine when an index would be worth implementing, based on a breakeven analysis between query execution, index structure upkeep and use, and a simple amortisation of indexing-related costs (see Figure 1). Furthermore, this project aims to further reinforce the belief that indices should be used for high-dimensional data, and simultaneously providing a quantitative method to confirm whether to introduce these indices. One of the datasets used in the project was the publicly available spatial dataset of the public transport system in New York City. The other dataset that was utilised is a randomly generated table with a column containing a four-dimensional cube.
From the results obtained, one could conclude that the indexes were highly beneficial on large datasets. Also, when comparing the query plan chosen freely by the query planner with the manipulated query plans that were used, in most cases the query planner chose an execution plan similar to the one that was subjected to the involuntary index.
References/Bibliography:
[1] R. Bayer and E. McCreight, “Organization and maintenance of large ordered indexes,” Acta Informatica, vol. 1, p. 173–189, 1972.
Student: Corinne Portelli
Course: B.Sc. IT (Hons.) Software Development
Supervisor: Dr. Joseph G. Vella