Search-based Software Testing (SBST) is the reformulation of the test case generation problem as a search problem encountered when seeking to find the optimal feasible solution using meta-heuristic optimization techniques such as genetic algorithms [1]. Genetic Algorithms (GAs), inspired by the theory of natural selection. Indeed, they reflect the process of nature where the fittest individuals are more likely to reproduce and create offspring while allowing less fit individuals to reproduce in order not to kill diversity.
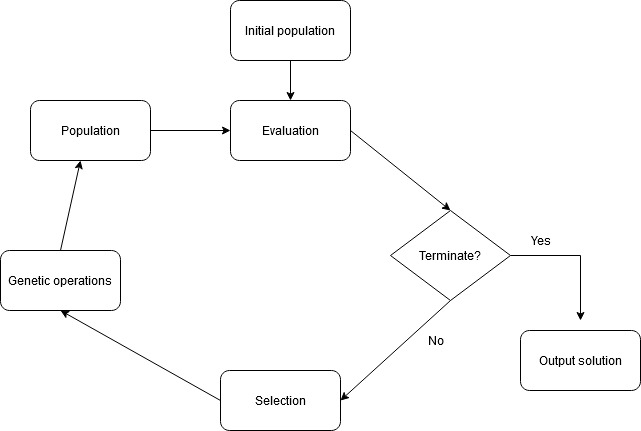
GAs manipulate a population of candidate solutions to an optimization problem. Selection provides the driving mechanism for the best solutions to survive. Each solution is assigned a fitness value that reflects its effectiveness when compared with other solutions related to the same problem. The higher its’ fitness, the higher its’ chances to survive and reproduce. Crossover and Mutation techniques are used to simulate the recombination of genetic material [2].
Due to a paradigm shift towards more decoupled microservices -based architectures, the access of features of an application from another application have become common practice using REST APIs . This study, set out to investigate the use of GAs in automatic test- case generation for a non-trivial REST API library, focusing on the effect of the fitness function and the state of the database. To investigate the effect of the fitness
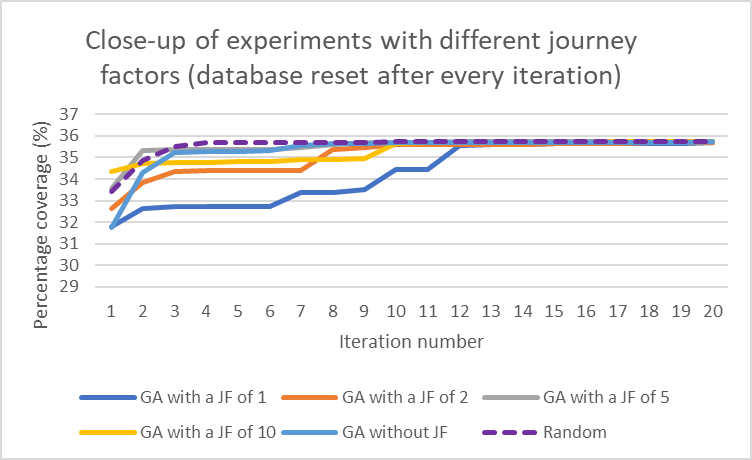
function, two fitness functions were developed. The first was based on code coverage. In a bid to improve the obtained results, the concept of journey factors and tours as used in exploratory testing were introduced in a second fitness function. To investigate the effect of the state of the database, this was reset a) after every iteration and b) after every test case in different experiments.
The experiments were carried out using an open- source REST API. In general, the GA did not surpass the results generated randomly in terms of code coverage. On evaluating this result, it was noted that the chosen REST API did not have a lot of interdependent calls. Nevertheless, the GA whose fitness function was influenced by an appropriate number of journeys, yielded better results than the GA with a fitness function based only on coverage. Furthermore, when evaluating the realism of the generated test cases, those generated by the GA compared better with the tests written by a human tester than those generated by the random approach.
The GA was affected by the state of the database, with the experiments in which the database was reset after every iteration converging much faster than the others. This lead to the conclusion that to achieve optimal results, the database should not be reset after each test case. In order that a GA could produce a good test suite, further work should be carried out such as experimenting with different REST APIs and finding the best possible parameters- possibly also refining the fitness functions.
References/Bibliography:
[1] P. McMinn. Search-based software test data generation: a survey. Software testing, Verification and reliability, 14(2):105-156, 2004.
[2] M. Srinivas and L. M. Patnaik. Genetic algorithms: A survey. computer, 27(6):17-26, 1994.
Student: Christina Gatt
Course: B.Sc. IT (Hons.) Computing Science
Supervisor: Dr. Mark Micallef