Classification between two classes of objects is a common- use case for the creation of machine learning models. The general practice is to create a model consisting of a single binary classifier that could discriminate between the classes by putting the examples of the first class on one side of a generated decision boundary, and the examples of the second class on the other. However, it is often the case where it would be necessary to discriminate between more than two classes, which is a problem known as ‘multi-class classification’ [1].
A popular strategy adopted by multiple models is to use an ensemble of binary classifiers, built using some paradigm. These would collectively be able to discriminate between the series of classes. The paradigm, which would determine how the binary classifiers are built and interact with one another, is the focus of this project. Traditional paradigms have some notable limitations, such as scaling up poorly to very large datasets, necessitating the retraining of the entire model from scratch when a small update would be required. These updates may consist of adding more data related to current classes, or even including new classes, thus requiring an increase in classifiers. A prominent paradigm that harbours these limitations is One vs Rest [2], which builds a classifier for each class, such that each classifier uses all the examples from every class. Since the time taken to train each classifier would depend on the total number of training examples, this paradigm would take a long time to train on large datasets.
In an effort to overcome some of these limitations, this study presents three novel paradigms for multi- class classification. The starting point is Similarity Based Learning (SBL), followed by the One vs Previous (OvP) method (Diagram (a) in the accompanying image). Lastly, these two would be combined into a modified
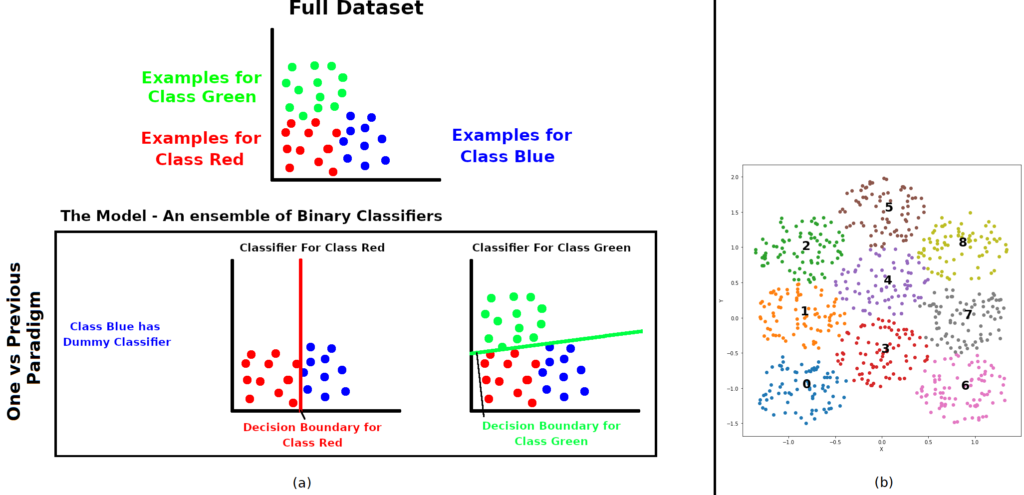
(b) Visualisation of synthetic dataset
algorithm of SBL (OvPSBL). The novel paradigms attempt to minimise the issue of poor scaling by decreasing the number of training examples required by each classifier. Moreover, in the event of new data entering the system, retraining from scratch could be avoided by decoupling the classifiers. This would require the retraining of certain classifiers only, rather than the entire model, thus making the novel paradigms suitable in both normal classification scenarios as well as lifelong machine learning [3, 4].
In this study, three paradigms have been evaluated over a purposely defined synthetic dataset (Diagram (b) in the accompanying image) as well as a real-world dataset (SpatialVOC2k) [5]., The presented paradigms were compared to a baseline paradigm so as to demonstrate how these scale up when changing the dataset characteristics, in relation to each other and traditional methods. Results show that, under most conditions, the studied paradigms are more efficient than current methods, whilst retaining a good classification accuracy. Furthermore, different paradigms work better than others in different situations. While this project offers a preliminary outline of how the paradigms perform, future work would help uncover further improvements and shed light on scenarios where certain paradigms would be more effective than others.
References/Bibliography:
[1] M. Aly, “Survey on multiclass classification methods,” in Technical Report, Caltech, 2005.
[2] R. Rifkin and A. Klautau, “In defense of one-vs-all classification,” Journal of Machine Learning Research, vol. 5, pp. 101-141, 12 2004.
[3] D. Silver, Q. Yang, and L. Li, “Lifelong machine learning systems: Beyond learning algorithms,” in AAAI Spring Symposium: Lifelong Machine Learning, 03 2013.
[4] A. Blum, “On-line algorithms in machine learning,” in Developments from a June 1996 Seminar on Online Algorithms: The State of the Art, (Berlin, Heidelberg), pp. 306-325, Springer-Verlag, 1998.
[5] A. Belz, A. Muscat, P. Anguill, M. Sow, G. Vincent, and Y. Zinessabah, “Spatialvoc2k: A multilingual dataset of images with annotations and features for spatial relations between objects,” in Proceedings of the 11th International Conference on Natural Language Generation, (Tilburg University, The Netherlands), pp. 140”145, Association for Computational Linguistics, Nov. 2018
Student: Daniel Cauchi
Course: B.Sc. IT (Hons.) Computing Science
Supervisor: Prof. Ing. Adrian Muscat