Fake News is a contemporary problem which causes serious social harm. People have been killed because of false assertions on online media [1] [2]. Early detection of fake news is therefore a critical problem in machine learning and NLP (Natural Language Processing); and a very challenging one.
This study attempted to automatically classify short claims, related to US politics, according to six levels of veracity, ranging from ‘True’ to “Pants on Fire” (ie. complete fabrications). These statements, taken from the LIAR dataset [3], were fact checked and pre-classified by experts for Politifact.com.
news classification
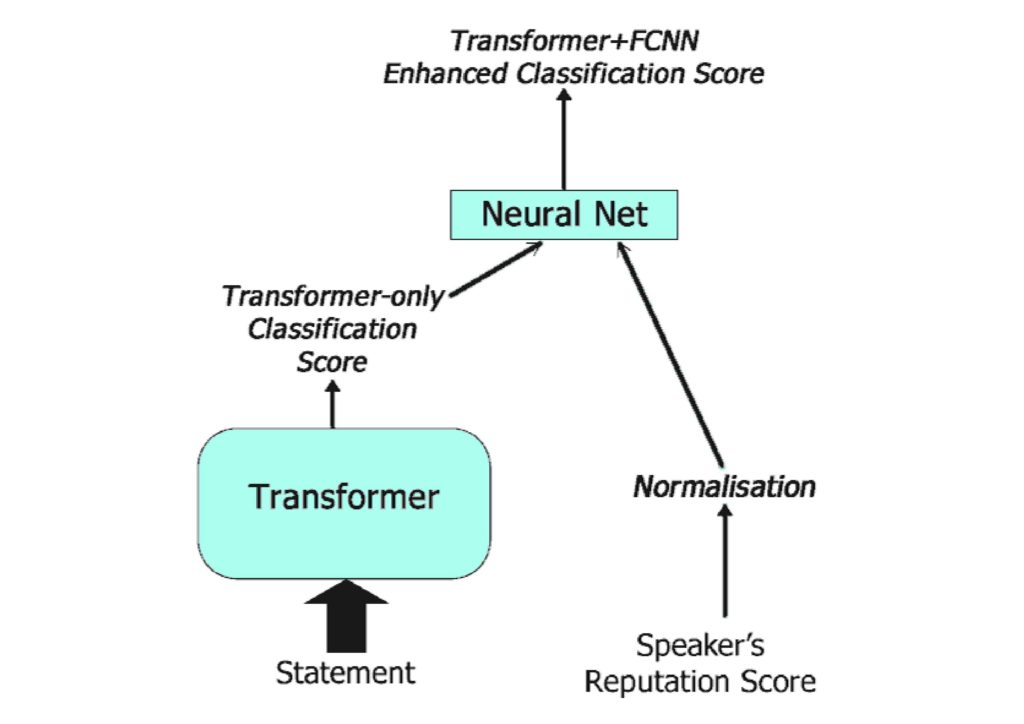
In order to achieve a better accuracy score than previous studies, state-of-the-art, machine learning models known as transformers were used. Transformers are Deep Learning architectures meant to improve language understanding. Among these were Google’s BERT [4]. BERT is the same language processing model that is used by the leading search engine to understand complex search queries. Other transformers like RoBERTa and ALBERT were also used. Such models have previously performed significantly well on several NLP tasks. To improve the classification of the claims, a simple neural network was also used to augment the transformer models so that they could utilise the claim maker’s reputation score, thus enhancing the overall classification (Figure 1).
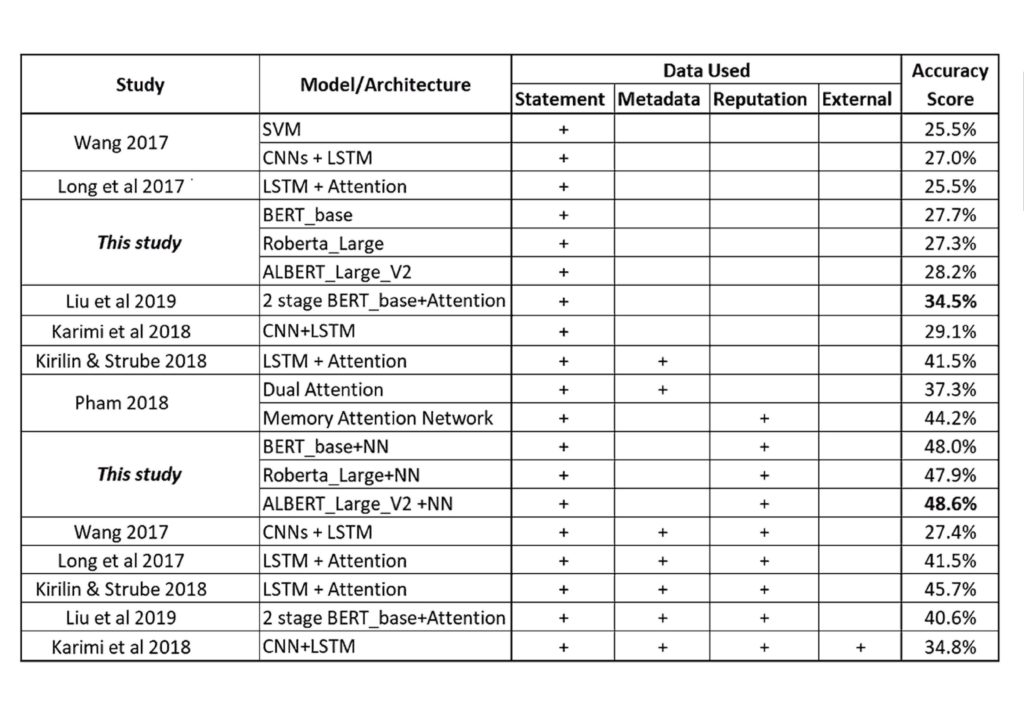
While the higher accuracy score was indeed achieved (Figure 2), the methods’ ability to help mitigate the real-life problem of fake news’ early detection, was still questionable. Flaws in the LIAR dataset were found, raising doubt about the validity of studies that used this dataset. For this reason, further experiments were done on the models built, to test their reliability. Flaws found in the models are discussed. Flaws include bias and the fact that they does not really model veracity which makes them prone to adversarial attacks.
It was noticed that the statements in the dataset would require knowledge of the real world to accurately label as either true or false. The question inevitably arose about whether purely NLP-based, fake news classification, in general, can really be used to detect deception or whether it is an ill-posed problem. A critique ofthis area of study was done. After scrutinising this study’s own models, previous meta- studies and psychological studies about detecting deception, the author presents the argument that language-based, fake news classification should be treated as an ill-posed (unstable) problem. Some potential solutions to stabilise the problem in future studies are also suggested.
References/Bibliography:
[1] India’s fake news problem is killing real people. https://asiatimes.com/2019/10/indias-fake-news- problem-is-killing-real-people/
[2] ‘Hundreds dead’ because of Covid-19 misinformation. https://www.bbc.com/news/world- 53755067
[3] William Yang Wang. 2017. “Liar, Liar Pants on Fire”: A New Benchmark Dataset for Fake News Detection. ACL (2) 2017: 422-42.
[4] Devlin, J., Chang, M.W., Lee, K., Toutanova, K. 2019. BERT: pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT).
[5] Ray Oshikawa, Jing Qian, William Yang Wang. 2018. A Survey on Natural Language Processing for Fake News Detection. ArXiv, abs/1811.00770.
[6] Chao Liu, Xinghua Wu, Min Yu, Gang Li, Jianguo Jiang, Weiqing Huang, Xiang Lu. 2019. A Two-Stage Model Based on BERT for Short Fake News Detection. In Douligeris C., Karagiannis D., Apostolou D. (eds) Knowledge Science, Engineering and Management. KSEM 2019. Lecture Notes in Computer Science, vol 11776. Springer, Cham.
Student: Mark Mifsud
Course: B.Sc. IT (Hons.) Software Development
Supervisor: Dr. Colin Layfield
Co-supervisor: Dr. Joel Azzopardi