The function of the Large Hadron Collider (LHC) is to allow hadrons (e.g. protons, neutrons) to collide at great speed, for the purpose of analysing the outcomes in order to gain a greater understanding of matter at the subatomic level. To achieve this, the LHC has been designed to consist of two circular, concentric beam pipes, each containing a particle beam circulating in opposing directions. There are four points at which the beam pipes cross over to bring about collisions. Superconducting magnets are used to direct the beams into their circular path along the pipes, and to focus the beams before the crossover points to increase the likelihood of collisions.[1]
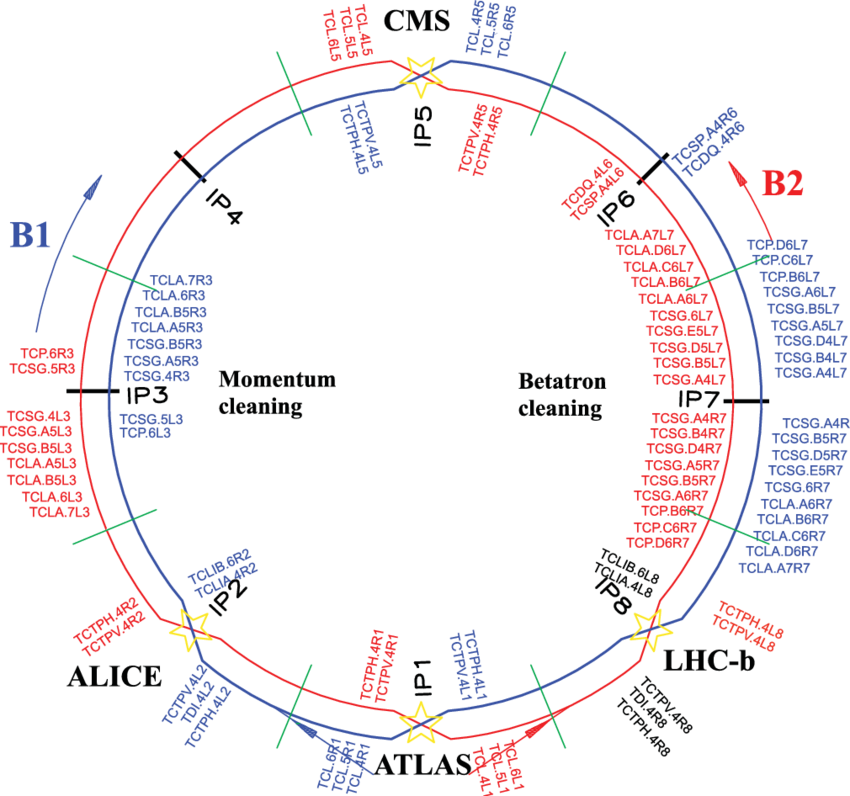
A cross-section of the beam pipe reveals that the particles form a normal distribution, with most of the particles being drawn towards the centre of the beam pipe. The particles furthest away from the centre are collectively known as the beam halo. Special devices – collimators [2] are placed at certain points around the beam pipes to absorb the beam halo. If not absorbed, the beam halo could damage equipment, e.g. superconducting magnets might be quenched, or could cause noise obfuscating the desired results concerning the beam collisions.[3] Beam- loss monitors (BLMs) are therefore used to detect the presence of a beam halo. If dangerously high losses would be detected, the beams could be terminated.[4]
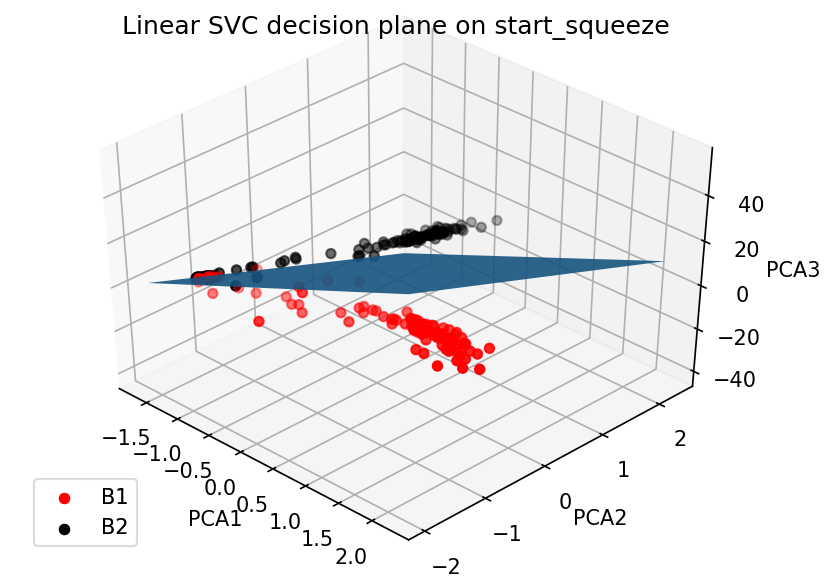
In theory, LHC beams should be symmetric, but this is not necessarily the case in practice. Symmetric BLMs (e.g.TCP.6R3 and TCP.6L3) were paired into single features, and supervised and unsupervised machine learning techniques were used (KMeans, DBSCAN clustering, linear SVM) to discover discrepancies between the BLM readings of the two beams. Each technique varied in its ability to separate the BLM data into two clusters (or classes on either side of a decision boundary, in the case of linear SVM.) A low separability would suggest minimal discrepancies between the losses of the two beams. The technique that could separate the data most efficiently was linear SVM, almost perfectly separating (and therefore classifying) the data into Beam 1 losses on one side of the decision boundary, and Beam 2 losses on the other. This indicates that discrepancies between the two beams are indeed significant.
References/Bibliography:
[1] https://lhc-machine-outreach.web.cern.ch/lhc-machine-outreach/beam.htm
[2] https://home.cern/news/news/experiments/collimators-lhcs-bodyguards
[3] https://home.cern/news/news/accelerators/crystal-cleaning-lhc-beam
[4] https://www.worldscientific.com/doi/pdf/10.1142/S0217751X13300354 4.11.2.
Student: Michael Vella Zarb
Course: B.Sc. IT (Hons.) Computing Science
Supervisor: Dr. Ing. Gianluca Valentino