Football is one of the world’s most popular sports, with a massive fan base and generating annual revenues of billions of euros. This has raised the necessity for accurately predicting the outcome of football matches. It has always been a challenging task to predict the outcome of a football match, not only for fans but also for punters and bookmakers. This is largely because there are multiple factors that could significantly influence the result, including: the team’s form throughout a season, weather conditions, and playing style. This study seeks to provide a comprehensive overview of the different methods employed to predict the outcome of football matches through the implementation of machine learning (ML) algorithms.
ML models have proven to be highly effective in predicting the outcome of football matches, since they tend to take into account a wide range of factors. Furthermore, these models use historical data to uncover patterns and trends that could subsequently be used to make predictions. The particular objective of this study was to predict the full-time result of a football match, which could be classified as one of three possible outcomes: win, draw, or loss.
The first step in predicting the outcome of a match would be to collect and preprocess the data, which often comprises information about the teams, such as their rankings, player statistics, previous matches, and other factors. The necessary data, would be collected through a custom-built web-scraper. In the case of this study, the data collected focused on the English Premier League, which is widely recognised as one of the most popular leagues in the world. Furthermore, it covered a variety of factors that were deemed likely to influence the outcome of matches. Subsequently, the data was preprocessed to make it suitable for utilisation in ML algorithms. The preprocessing stage included data cleaning, feature selection, and data normalisation. This step ensured that the data would be of high quality, complete and relevant to the task.
The data was then divided into training and testing sets using an 80:20 ratio split. The training set was used to train the model, while the testing set was used to evaluate its performance. In previous studies logistic regression, random forest, and neural networks were among the most frequently employed algorithms for developing a predictive model. These algorithms differ in terms of complexity, accuracy, and speed. This study applied ML algorithms to conduct a comprehensive and comparative analysis of a number of these algorithms in the field of football-match prediction while also taking features and statistics into account.
After applying the algorithms on the acquired data, it was essential to assess the performance of the resulting model. This step is particularly significant as it helps to determine the model’s ability to predict the results of matches accurately. Several metrics, such as recall, precision, accuracy, and F1-Score, were used to evaluate the model. Furthermore, the mean squared error and mean absolute error evaluation metrics were also used to assess performance. These metrics were crucial in analysing the model’s performance and identifying any areas for improvement.
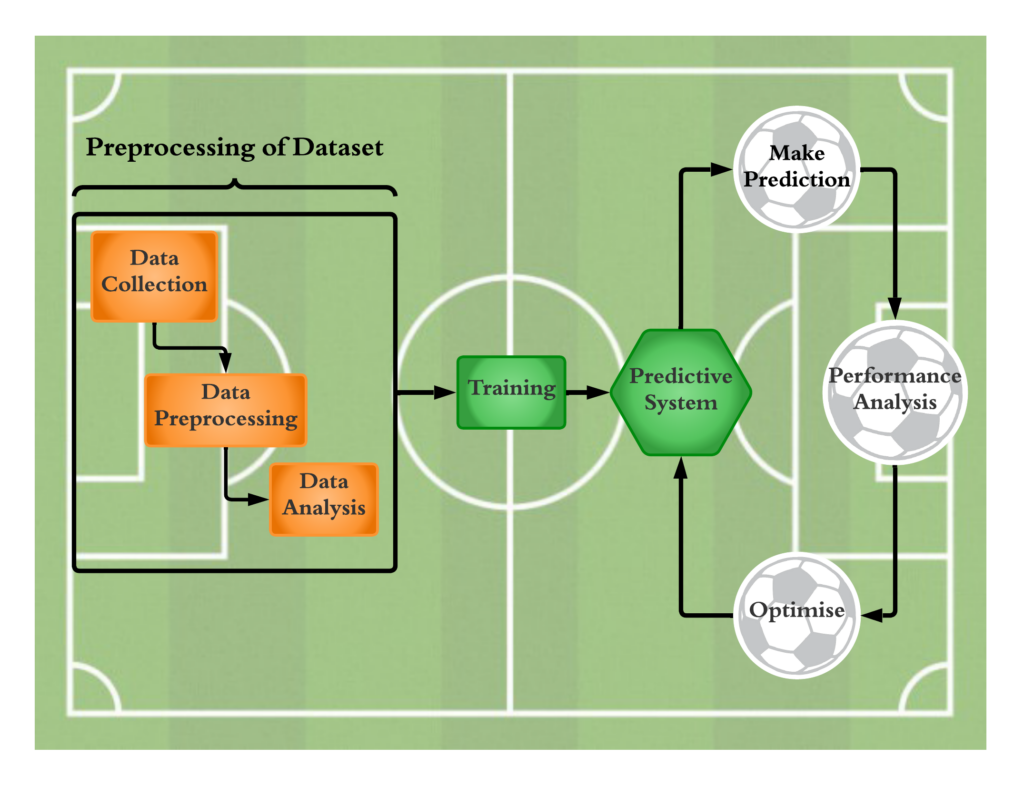
Figure 1. The various steps involved in using machine learning to predict the outcome of football matches, beginning with data collection and concluding with model optimisation
Student: Darren Saliba
Supervisor : Dr Charlie Abela