The Voynich manuscript (VMS) is a codex written in a script yet undeciphered, and believed to date back to the Middles Ages. To date, none of the many attempts at deciphering the codex have yielded entirely conclusive results. Nevertheless, the ongoing research on this manuscript has brought to light invaluable insights in diverse fields of study.
Throughout the years, several theories were formed, which could be generally classified into one of the following conclusions about the manuscript: a fabrication, a cipher, or a natural language in an unfamiliar script.
To allow computer-aided analysis and machine processing on the script (including statistical analysis) digital transliteration files were transcribed from the manuscript’s text using an ASCII (American Standard Code for Information Interchange) alphabet. A standard file format, known as Intermediate Voynich MS Transliteration File Format (IVTFF), has been constructed to ensure consistency when representing the script in a transliteration file, enabling the development of standardised digital tools. This provided the basis for this project.
This research sought to develop a tailor-made software that would graphically display the data from these transliterations, thus allowing the user to enter several regular expressions for the software to highlight any matching patterns throughout the text, including substrings, prefixes, and suffixes. The software would be able to provide statistical analyses, including measures of central tendency, on these regular expressions; it would also construct graphs that could provide a visual representation of each analysis for comparison with other search patterns. This tool could be used in exploring the manuscript to search for evidence to corroborate the respective hypotheses from previous studies, including manuscript classifications, such as the Hoax Hypothesis, and authorship attributes, amongst other studies.
This study allows pattern visualisation and comparison of text from the VMS with mediaeval languages, to test whether the roots of this script came from a natural, perhaps Romance, language. The qualitative and quantitative methodologies applied sought to broaden the horizons of the research while contributing to the worldwide research aimed at deciphering the manuscript conclusively.
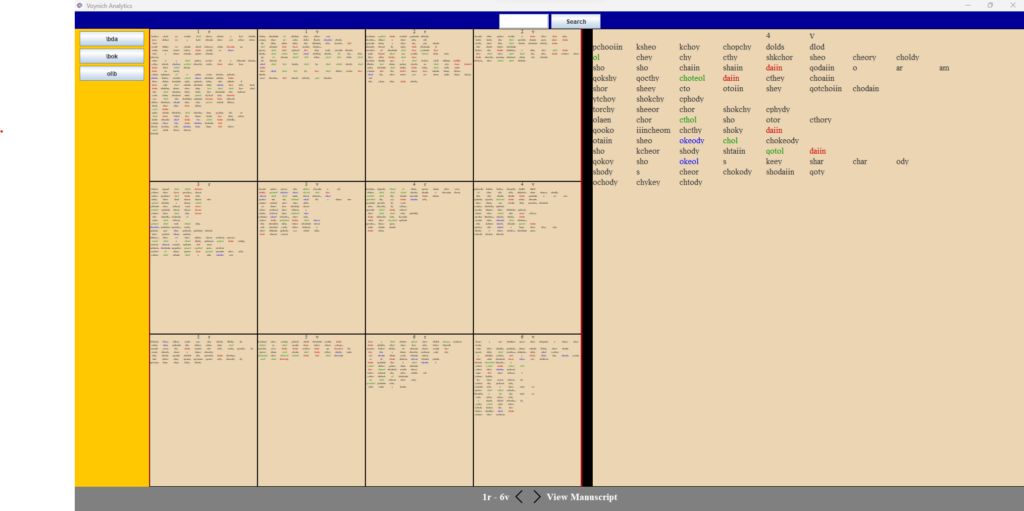
Figure 1. The application demonstrates a number of regular terms and expressions
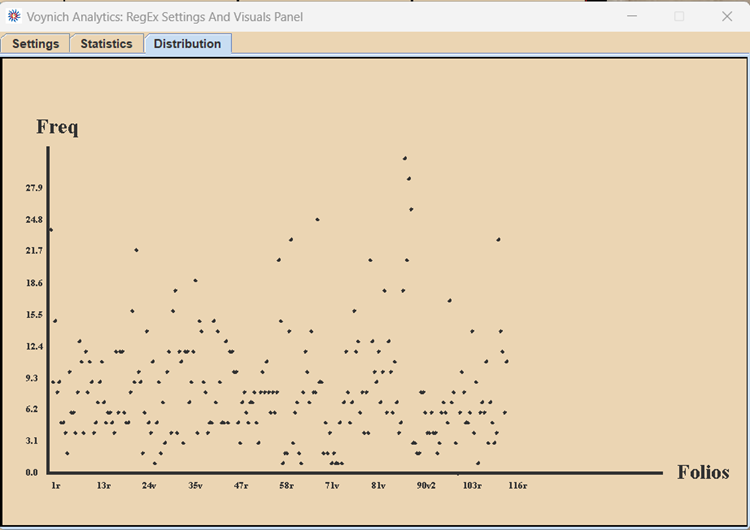
Figure 2. This graph, generated by the software, shows the number of occurrences of words beginning with the syllable ‘da’ throughout the manuscript
Student: Matthew Amaira
Supervisor : Dr Colin Layfield